Probability and Statistics >Basic Statistics > What is a Statistic? Contents:
- What is a Statistic?
- What is the Difference Between Inferential and Descriptive Statistics?
- Notation
- Data & Variables
- Vital Statistics & Estimators
What is a Statistic?
Statistics are everywhere. From the news to the classroom, we are constantly surrounded by data that can help us gain a better understanding of any given topic. But exactly what is a statistic? In its simplest form, it is a fact or piece of data from a study of a large quantity of numerical data. For example, the statement “the statistics show that the crime rate has increased” is referring to facts or numbers collected from research involving crime rates. More precisely, a statistic is a small piece of data from a portion of a population. It’s the opposite of a parameter — which is census data that surveys everyone. Think of it this way:
- If you calculate something (e.g., an average) from part of a data set, that’s a statistic.
- If you know something about 10% of people, such as their favorite TV show, that’s a statistic also.
- If you survey everyone in the United States to get their voting preference, that’s a parameter. Parameters contain all of the information. And all the information is rarely known, which is why we need statistics.
An important difference between parameters and statistics is that a statistic is a variable that can vary from sample to sample, while a parameter is a constant that does not change.
| Statistic | Parameter | |
|---|---|---|
| Description | Describes a sample. | Describes a population. |
| Calculation | Calculated from a sample. | Calculated from the whole population. |
| Value | Variable, depending on the sample. | Fixed. |
The most common statistic is the mean. It represents the average of a dataset.
Other common statistics include the median and the mode. The median is the middle value in a sorted dataset, while the mode refers to the most commonly occurring value. These measures also provide insights into the central tendency of the data, but in different ways compared to the mean.
Other statistics you’ll often come across include:
- Range: Determines the gap between the highest and lowest values in a dataset.
- Variance: How the data is spread out.
- Standard deviation: Quantifies the amount of variation from the mean.
- Correlation: Measures the relationship between variables.
Examples
Statistics are drawn from populations, but a “population” doesn’t necessarily mean a physical count of bodies. It can be a collection of just about anything you can count, from galaxies in the sky to a count of trials in an experiment. Thus a statistic can be any quantity calculated from sample values. A couple of examples:
- The average height of a man in the world is 5’10” [2]. This is a statistic because it describes a population, in this case the population of men in the world. In real life, we never survey everyone — asking all 3+ billion men in the world isn’t possible, so when you read a fact like this about the “world”, it is always a statistic.
- The probability of flipping a coin and getting tails is 50%. This is a statistic because it tells us the probability of an event happening, in this example the event of flipping a coin and getting tails. We aren’t endlessly flipping coins until infinity, or flipping all of the coins in the world — we are using a small amount of coins and flipping them a set amount.
Here are some other examples of statistics:
- The unemployment rate in the United States averaged 5.72% from 1948 to 2023.
- The average life expectancy for a man in the United States is 77.28 years.
- The median household income in France is $61,020.
What is a statistic used for?
Statistics helps us to understand the data that is collected about us and the world. For example, the UPS database is 17 terabytes — about as large as a database containing every book in the Library of Congress [1]. All of that data is meaningless without a way to interpret it, which is where statistics comes in.
Statistical methods are used in many areas such as economics, finance, health care and marketing. For example, statistics can be used to analyze market trends in banking and finance, evaluate patient outcomes in healthcare, or determine the best crops to grow in agriculture.
Statistical methods also allow us to compare different types of data so that we can make more accurate predictions about future events or outcomes. For example, let’s say we wanted to know whether an increase in advertising spending would lead to an increase in sales for an organization. We could use methods such as regression analysis in order to determine this with greater accuracy than just relying on intuition alone.
Statistics also enables us to draw conclusions from data that would otherwise be impossible or too costly to measure directly, such as testing a new drug on everyone in the world; this allows us to explore new avenues of research that would not be possible without statistics.
Types
Stats come in three types:
- Descriptive Statistics. Describe data. Includes sample mean or sample median. Order statistics are a subset of descriptive statistics. They tell you something about how the data is ordered. For example, measurements like the sample minimum. You know the order is #1. Also includes charts and graphs. Anything that describes data is descriptive statistics.
- Estimators.Used to guess at a parameter. In other words, something about a population. Often taken from descriptive stats. For example, if you know the sample mean you can use it to guess what the population mean is. Used in inferential statistics. Inferential stats is just a “best guess” about something, based on data.
- Test Statistics, which are used in null hypothesis testing. That’s where you take a known fact about a population and then test that fact to see if it is true or not. A “population” could be real people in a trial. Or it could be TVs in a factory. Which test statistic you use depends on what kind of data you have. Some examples of test stats: t score, and chi-square.
A statistic can be more than one type. For example, the sample standard deviation can be used as a descriptive statistic to describe the standard deviation of a sample. It can be used as an estimator: To estimate the population standard deviation. And it can be used to test a theory (a hypothesis).
Origin of “statistic”
The word statistic indirectly comes from the medieval Latin word status, for a political state although there is also a closely related word in German (statistik) which is also used in a political sense. “Statistik” was popularized by German political scientist Gottfried Aschenwall (1719-1772) in his “Vorbereitung zur Staatswissenschaft” (1748).
According to Leiden University, it’s difficult to know exactly when the word ceased to have a meaning close to a “political state” and became more of a mathematical term. The first time the word was used in the Oxford English Dictionary is in 1770, in W. Hooper’s translation of Bielfield’s Elementary Universal Education:
“The science, that is called statistics, teaches us what is the political arrangement of all the modern states of the known world.”
The Online Etymology Dictionary states that the first recorded time the word meant “numerical data collected and classified” was 1829 and the abbreviated form stats first appeared in 1961. Webster’s 1828 dictionary defines statistics as:
A collection of facts respecting the state of society, the condition of the people in a nation or country, their health, longevity, domestic economy, arts, property and political strength, the state of the country, &c.
What is the Difference Between Inferential and Descriptive Statistics?
Inferential means that you can infer (make predictions) from the data, while descriptive means that you just describe the data. Let’s say you worked every week last month and received four paychecks: $100, $105, $110, and $120. Examples of descriptive statistics about your pay (describing and summarizing the set of data) Some options available to you:
- Find the mean (the average) = $100 + $105 + $110 + $120 / 4 = $108.75. You earned an average of $108.75 last week. You could also calculate other statistics about your pay like the median, range or standard deviation.
- Make a bar graph:
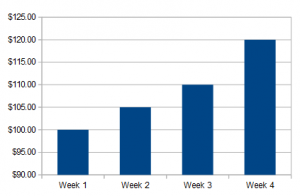
You could also make other charts like a pie chart, a line graph or a stem plot and you could also describe the shapes of those distributions (i.e. bell-shaped, skewed, or uniform).
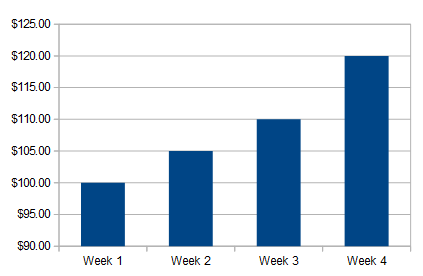
Examples of inferential statistics about your pay (making predictions): Perhaps the most obvious inference you can make from your pay is that there’s an upwards trend. It looks like it’s going up by $5 per week, so you can expect to earn $125 in week 5. You can quantify this trend by:
- Inserting a trendline: this is easy to do in Microsoft Excel (instructions can be found here). You could also draw a rough line by hand–grab a ruler, draw a pencil line, and make your predictions based on where the line is going. For your pay, the line is going upwards (it should have a positive slope).
- If you want an equation for the trendline, you can perform regression analysis, enabling you to easily predict what you’ll earn next, week, next month, or next year.
- More complex inferential statistics include hypothesis testing, where you take raw data and use a known model to verify the accuracy of your predictions. For this pay check example, you might compare your pay to the average pay of someone else working in your particular field.
What is a Statistic: Notation
In general, stats notation is in Roman letters, a-z. Parameters have Greek letters or uppercase Roman). If some letters look the same: look closely. For example, look for the small p and large P. Usually, if you see a large letter (i.e. P), it’s a parameter. Small letters usually mean it’s a stat.
| Measurement | Statistic (Roman or lowercase) | Parameter (Greek or uppercase) |
| Population Proportion | p | P |
| Data Elements | x | X |
| Population Mean | μ | |
| https://www.statisticshowto.com/probability-and-statistics/standard-deviation/ | s | σ |
| Variance | s2 | σ2 |
| Number of elements | n | N |
| Correlation Coefficient | r | ρ |
What is a Statistic: Data & Variables
You might think that data is a list of numbers. However, in statistics, “Data” means something a little different; Data contains the who and what about something (the “something” could be anything from a book in a bookstore to a batting average to a choice about elections).
Data can have numerals that have meaning. For example, 1453767142 is the ISBN for the Practically Cheating Statistics Handbook. The What as it related to ISBNs is the name of the book (The Practically Cheating statistics Handbook) and the Who as it related to book sales could be the person who ordered the book or it could be the purchase orders (as opposed to the individuals who placed those orders).
You might be familiar with variables from algebra, like “x” or “y.” They stand for something (usually a number that you plug-in to solve an equation). In statistics, variables are broken down into two types: numerical or quantitative variables and categorical variables.
- Numerical variables are the variables you’re most familiar with: numbers. For example, those “x” and “y” variables in algebra stand for a number.
- Categorical variables are variables that aren’t numbers: they are descriptive. For example, sex (male or female), occupation, school district, state and dog breeds are all types of categorical variables.

What is a Statistic: Vital Statistics

Vital statistics can mean one of three things, as far as stats goes:
- National Vital Statistics System (run by the CDC) government records), a government database that keeps records of births, deaths, marriages, divorces, and fetal deaths.
- Bust-waist-hip measurements: measurements for clothes fitting, usually listed on a clothing size chart.
- Vital signs: Blood pressure and other body measurements taken by health professionals. For example, blood pressure and pulse are used to measure the health of your heart.
What is an Estimator?
An estimator (or estimate) is a statistic that’s used to approximate a population parameter. While there are several types of estimators, the word “estimator” on its own usually refers to a point estimate. A point estimate is a single value (as opposed to an interval, like a confidence interval). For example, the mean is a point estimate. The two characteristics of point estimates that are arguably most important are:
- Bias: whether the estimator underestimates or overestimates a parameter. For example state inspectors in Houston, Texas, found that one in five gas pumps weren’t calibrated correctly. An incorrectly calibrated pump could cost a consumer up to 18 cubic inches per five gallons pumped. The bias meant that consumers were consistently overcharged. We can void bias by using unbiased estimators such as the sample mean, which will give an expected value that is equal to the true population parameter [3].
- Sampling variability: Your average bathroom scale probably goes up and down like a yoyo, stating a slightly different weight every time you get on it. Your weight might range from 158.1 one minute, to 161.2 the next. However, if you take a large enough sample (say, 30 measurements), your actual weight would probably be close to the mean of these readings. The widespread of weights (anywhere from 158.1 to 161.2) is one example of variability between samples. Sampling variability is usually measured in terms of standard error. The larger the standard error, the larger the sampling variability.
What is a statistic in the national vital statistics system?
The National Vital Statistics System is a database run by the Centers for Disease Control (CDC). Although the individual states are responsible for actually registering the data, the CDC collaborates with the National Center for Health Statistics, the National Cancer Institute and the Census Bureau to keep an up-to-date database of life and death statistics for the United States. Included are: births, deaths, marriages, divorces, and fetal deaths. Additional programs related to the National Vital Statistics System include:
- The Linked Birth and Infant Death Data Set explores the connection between infant deaths and risk factors present at birth.
- National Survey of Family Growth. Collects information on family life, marriage and divorce, pregnancy, infertility, use of contraception, and the health of men and women.
- The Matched Multiple Birth Data Set keeps records on twins, triplets and quadruplets.
- National Death Index is a computerized index of death records. It is not available to the general public.
- The National Maternal and Infant Health Survey was conducted in 1988 and studied pregnancy risk factors for poor pregnancy outcomes like stillbirth and low birth weight.
- The National Mortality Followback Surveyattempted to find factors that affected mortality, like socioeconomic status, disability of use of health care facilities.
References
- Bock, Velleman, & DeVeaux, Stats: Modeling the World – Chapter 1: Stats Starts Here.
- The Average Height of Men and Women Worldwide
- Kokoska, Stephen (2015). Introductory Statistics: A Problem-Solving Approach (2nd ed.). New York: W. H. Freeman and Company.