Hypothesis Testing > Uniformly Most Powerful (UMP) Test
What is a Uniformly Most Powerful Test?
Uniformly Most Powerful tests (UMP tests) have the highest power among all possible alternate hypotheses of the same alpha level.
The existence of UMP is not guaranteed, particularly when the test involves nuisance variables that are irrelevant to your study. Nonetheless, if UMP is present, the Neyman-Pearson lemma (NPL) can help identify it.
A UMP test is usually defined in terms of a uniformly most powerful rejection region (UMPCR), also called a “critical region.” A region C with a size of α becomes the UMPCR for testing a simple null hypothesis against a set of alternate hypotheses, if it represents the “best” critical region. The “best” critical region minimizes the probability of committing Type I or Type II errors. It is also the region that provides a UMP test with the largest (or equally largest) power function.
UMP vs. UMPU
A uniformly most powerful unbiased (UMPU) test denotes a test that not only holds the most powerful rejection region for all alternative hypothesis values but is also unbiased.
To put that differently, a UMPU test is a UMP test that also meets the requirement of being unbiased; An unbiased test has an alpha level that is equal to the probability of rejecting the null hypothesis.
For example, a UMP test for a one-sample t-test involves rejecting the null hypothesis if the absolute value of the t-statistic exceeds a critical value based on the significance (alpha) level and sample size. This test is unbiased. It ensures that the probability of rejecting the null hypothesis, assuming it is true, aligns with the test’s alpha level. However, this test is not UMPU since there are other tests that have higher power across all possible alternate hypotheses.
With an UMPU one-sample t-test, you must reject the null hypothesis if the absolute value of the t-statistic is greater than a critical value that depends on the alpha level, population variance, and sample size. It is UMPU as it features the most powerful rejection region for all potential alternate hypotheses — while being unbiased at the same time.
Generally, UMPU tests pose more challenges to find than UMP tests. But they are often preferred since they offer the highest power against all alternative hypotheses and unbiasedness.
Uniformly most powerful test and the Neyman-Pearson Lemma
The Neyman-Pearson lemma can help identify the best hypothesis test when dealing with a simple null and alternate hypothesis. Simple means that they are both statements of a single population parameter and do not contain inequalities. For example,
- Null hypothesis: The mean weight of men in the United States is 220 pounds.
- Alternate hypothesis: The mean weight of men in the United States is not 240 pounds.
In the case of composite (multiple) hypotheses, the NPL can be extended to evaluate each individual alternate hypothesis. Composite hypotheses offer multiple potential solutions. For example, the composite hypothesis H0:σ2 > 8 does not specify a particular value for σ2; it could be any value greater than 8. The basic idea is to test each simple hypothesis individually to determine if it is the most powerful among all possibilities.
Definitions using UMP and Likelihood-Ratio
Uniformly most powerful tests can be defined more formally as
“Let C be a class of tests for testing H0: θ ∈ Θ0 versus H1: θ ∈ Θc1. A test in class C, with power function β(θ), is a uniformly most powerful (UMP) class C test if β(θ) ≥ β′(θ) for every θ ∈ Θ0c and every β′(θ) that is a power function of a test in class C.” G. Casella and R. Berger [1].
This is no different from the informal definition I stated at the beginning of this article: the UMP test is the one with the biggest power function (out of all tests of the same size α). The power function tells us how likely we are to reject the null hypothesis if the true value of the parameter is θ and Θ0 is the set of all possible values for θ under the null hypothesis.
Let’s take a closer look at the statement:
- Let C be a class of tests. This is saying that C is a set of hypothesis tests with the same null and alternative hypotheses.
- for testing H0: θ ∈ Θ0 versus H1: θ ∈ Θc1. This means that all tests in C are used to test the null hypothesis that the parameter θ belongs to the set Θ0. This is against the alternative hypothesis that θ belongs to the set Θc1.
- A test in class C, with power function β(θ). We are considering one test in the class C, and its power function is β(θ).
- is a uniformly most powerful (UMP) class C test. The test is UMP in class C.
- if β(θ) ≥ β′(θ) for every θ ∈ Θ0c and every β′(θ) that is a power function of a test in class C. This is telling us that the test’s power function β(θ) is greater than or equal to the power function β′(θ) of any other test in class C for every value of θ in the set Θ0c.
The same statement can be rewritten using the likelihood ratio test. Let’s say you had two simple hypotheses H0: θ = θ0 and H1:θ= θ1. In order to find the most powerful test at a certain alpha level (with threshold η), you would look for the likelihood-ratio test which rejects the null hypothesis in favor of the alternate hypothesis when 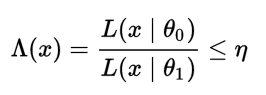
where ![]()
If you have an entire set of possibilities (which would be the case with composite hypotheses), each test should be tested individually using the above criteria.
References
- Casella, G. and Berger, R.L. (2002) Statistical Inference. 2nd Edition, Duxbury Press, Pacific Grove.