Contents:
- What is Experimental Design?
- Variables
- Validity in Experimental Design
- Types of Design
- Related Topics
1. What is Experimental Design?
Watch the video for an overview of experimental design:
Experimental design is a way to carefully plan experiments in advance so that your results are both objective and valid. The terms “Experimental Design” and “Design of Experiments” are used interchangeably and mean the same thing. However, the medical and social sciences tend to use the term “Experimental Design” while engineering, industrial and computer sciences favor the term “Design of experiments.”
Design of experiments involves:
- The systematic collection of data
- A focus on the design itself, rather than the results
- Planning changes to independent (input) variables and the effect on dependent variables or response variables
- Ensuring results are valid, easily interpreted, and definitive.
Ideally, your experimental design should:
- Describe how participants are allocated to experimental groups. A common method is completely randomized design, where participants are assigned to groups at random. A second method is randomized block design, where participants are divided into homogeneous blocks (for example, age groups) before being randomly assigned to groups.
- Minimize or eliminate confounding variables, which can offer alternative explanations for the experimental results.
- Allow you to make inferences about the relationship between independent variables and dependent variables.
- Reduce variability, to make it easier for you to find differences in treatment outcomes.
The most important principles1 are:
- Randomization: the assignment of study components by a completely random method, like simple random sampling. Randomization eliminates bias from the results
- Replication: the experiment must be replicable by other researchers. This is usually achieved with the use of statistics like the standard error of the sample mean or confidence intervals.
- Blocking: controlling sources of variation in the experimental results.
2. Variables in Design of Experiments
- What is a Confounding Variable?
- What is a Control Variable?
- What is a Criterion Variable?
- What are Endogenous Variables?
- What is a Dependent Variable?
- What is an Explanatory Variable?
- What is an Intervening Variable?
- What is a Manipulated Variable?
- What is an Outcome Variable?
3. Validity in Design of Experiments
- What is Concurrent Validity?
- What is Construct Validity?
- What is Consequential Validity?
- What is Convergent Validity?
- What is Criterion Validity?
- What is Ecological validity?
- What is External Validity?
- What is Face Validity?
- What is Internal Validity?
- What is Predictive Validity?
4. Design of Experiments: Types
- Adaptive designs.
- Balanced Latin Square Design.
- Balanced and Unbalanced Designs.
- Between Subjects Design.
- What are Case Studies?
- What is a Case-Control Study?
- What is a Cohort Study?
- Completely Randomized Design.
- Cross Lagged Panel Design.
- Cross Sectional Research
- Cross Sequential Design.
- Definite Screening Design
- Factorial Design.
- Flexible Design.
- Group sequential Design.
- Longitudinal Research.
- Matched-Pairs Design.
- Parallel Design.
- Observational Study.
- Plackett-Burman Design.
- Pretest-Posttest Design.
- Prospective Study.
- Quasi-Experimental Design.
- Randomized Block Design.
- Randomized Controlled Trial
- Repeated Measures Design.
- Retrospective Study.
- Split-Plot Design.
- Strip-Plot Design.
- Stepped Wedge Designs.
- What is Survey Research?
- Within subjects Design.
Between Subjects Design (Independent Measures).
What is Between Subjects Design?

In between subjects design, separate groups are created for each treatment. This type of experimental design is sometimes called independent measures design because each participant is assigned to only one treatment group.For example, you might be testing a new depression medication: one group receives the actual medication and the other receives a placebo. Participants can only be a member of one of the groups (either the treatment or placebo group). A new group is created for every treatment. For example, if you are testing two depression medications, you would have:
- Group 1 (Medication 1).
- Group 2 (Medication 2).
- Group 3 (Placebo).
Advantages and Disadvantages of Between Subjects Design.
Advantages.
Between subjects design is one of the simplest types of experimental design setup. Other advantages include:
- Multiple treatments and treatment levels can be tested at the same time.
- This type of design can be completed quickly.
Disadvantages.
A major disadvantage in this type of experimental design is that as each participant is only being tested once, the addition of a new treatment requires the formation of another group. The design can become extremely complex if more than a few treatments are being tested. Other disadvantages include:
- Differences in individuals (i.e. age, race, sex) may skew results and are almost impossible to control for in this experimental design.
- Bias can be an issue unless you control for this factor using experimental blinds (either a single blind experiment–where the participant doesn’t know if they are getting a treatment or placebo–or a double blind, where neither the participant nor the researcher know).
- Generalization issues means that you may not be able to extrapolate your results to a wider audience.
- Environmental bias can be a problem with between subjects design. For example, let’s say you were giving one group of college students a standardized test at 8 a.m. and a second group the test at noon. Students who took the 8 a.m. test may perform poorly simply because they weren’t awake yet.
Completely Randomized Experimental Design.
What is a Completely Randomized Design?
A completely randomized design (CRD) is an experiment where the treatments are assigned at random. Every experimental unit has the same odds of receiving a particular treatment. This design is usually only used in lab experiments, where environmental factors are relatively easy to control for; it is rarely used out in the field, where environmental factors are usually impossible to control. When a CRD has two treatments, it is equivalent to a t-test.
A completely randomized design is generally implemented by:
- Listing the treatment levels or treatment combinations.
- Assigning each level/combination a random number.
- Sorting the random numbers in order, to produce a random application order for treatments.
However, you could use any method that completely randomizes the treatments and experimental units, as long as you take care to ensure that:
- The assignment is truly random.
- You have accounted for extraneous variables.
Completely Randomized Design Example.
Let’s suppose you were conducting an experiment to see how a type of fertilizer (you have 4 different ones) affects the growth rate of 16 tomato plants in a greenhouse. The first step is to list the treatment levels. You have four fertilizers, so let’s call these ABCD. You have 16 plant locations, labeled 1-16.
First, write the numbers 1-16 in 16 pieces of equal sized paper and place them into a bowl. Next, write the letters A B C D on 16 separate pieces of paper (i.e. you’ll have 4 x As, 4 x Bs, 4 Cs and 4 Ds) and place them in another bowl. Select one piece of paper from the first bowl and one from the second to get a location and a treatment.
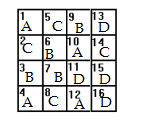
Some errors that could cause serious design flaws could include randomly assigning columns to treatments so that it’s easier to apply fertilizer to an entire column (for example, column 1 has fertilizer B, column 2 has fertilizer D and so on). While this may be convenient, you run the risk that the plants in row A and D have more access to sunlight as they are on the outside of the space.
Completely Randomized Design with Subsampling.
This subset of CRD is usually used when experimental units are limited. Subsampling might include several branches of a particular tree, or several samples from an individual plot.
Back to Top.
Factorial Design.
What is a Factorial Design?
A factorial experimental design is used to investigate the effect of two or more independent variables on one dependent variable. For example, let’s say a researcher wanted to investigate components for increasing SAT Scores. The three components are:
- SAT intensive class (yes or no).
- SAT Prep book (yes or no).
- Extra homework (yes or no).
The researcher plans to manipulate each of these independent variables. Each of the independent variables is called a factor, and each factor has two levels (yes or no). As this experiment has 3 factors with 2 levels, this is a 2 x 2 x 2 = 23 factorial design. An experiment with 3 factors and 3 levels would be a 33 factorial design and an experiment with 2 factors and 3 levels would be a 32 factorial design.
The vast majority of factorial experiments only have two levels. In some experiments where the number of level/factor combinations are unmanageable, the experiment can be split into parts (for example, by half), creating a fractional experimental design.
Null Outcome.
A null outcome is when the experiment’s outcome is the same regardless of how the levels and factors were combined. In the above example, that would mean no amount of SAT prep (book and class, class and extra homework etc.) could increase the scores of the students being studied.
Main Effect and Interaction Effect.
Two types of effects are considered when analyzing the results from a factorial experiment: main effect and interaction effect. The main effect is the effect of an independent variable (in this case, SAT prep class or SAT book or extra homework) on the dependent variable (SAT Scores). For a main effect to exist, you’d want to see a consistent trend across the different levels. For example, you might conclude that students who took the SAT prep class scored consistently higher than students who did not. An interaction effect occurs between factors. For example, one group of students who took the SAT class and used the SAT prep book showed an increase in SAT scores while the students who took the class but did not use the book didn’t show any increase. You could infer that there is an interaction between the SAT class and use of the SAT prep book.
Back to Top.
Matched-Pairs Design.
What is Matched Pairs Design?
Matched pairs design is a special case of randomized block design. In this design, two treatments are assigned to homogeneous groups (blocks) of subjects. The goal is to maximize homogeneity in each pair. In other words, you want the pairs to be as similar as possible. The blocks are composed of matched pairs which are randomly assigned a treatment (commonly the drug or a placebo).
For example, an experiment to test a new drug may have blocks of 200 males and 200 females. Each block contains 100 pairs, who are matched according to some criteria other than sex (like age, other medications, or health conditions). Each pair is then treated like a block, with each randomly assigned to receive the drug or a placebo. The following table shows experiment, where pair 1 could represent two healthy women age 29, pair 2 could represent two women age 29 with liver disease, pair 3 could contain two healthy women age 39, pair 4 could contain two women age 39 with liver disease, and so on.
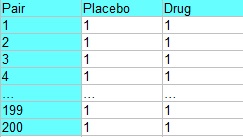
Stacking in Matched Pairs Design.
You can think of matched pair design as a type of stacked randomized block design. With either design, your goal is to control for some variable that’s going to skew your results. In the above experiment, it isn’t just age that could account for differences in how people respond to drugs, several other confounding variables could also affect your experiment. The purpose of the blocks is to minimize a single source of variability (for example, differences due to age). When you create matched pairs, you’re creating blocks within blocks, enabling you to control for multiple sources of potential variability. You should construct your matched pairs carefully, as it’s often impossible to account for all variables without creating a huge and complex experiment. Therefore, you should create your blocks starting with which candidates are most likely to affect your results.
Back to Top.
Observational Study
What is an Observational Study?
An observational study (sometimes called a natural experiment or a quasi-experiment) is where the researcher observes the study participants and measures variables without assigning any treatments. For example, let’s say you wanted to find out the effect of cognitive therapy for ADHD. In an experimental study, you would assign some patients cognitive therapy and other patients some other form of treatment (or no treatment at all). In an observational study you would find patients who are already undergoing the therapy , and some who are already participating in other therapies (or no therapy at all).
Ideally, treatments should be investigated experimentally with random assignment of treatments to participants. This random assignment means that measured and unmeasured characteristics are evenly divided over the groups. In other words, any differences between the groups would be due to chance. Any statistical tests you run on these types of studies would be reliable. However, it isn’t always ethical or feasible to run experimental studies, especially in medical studies involving life-threatening or potentially disabled studies. In these cases, observational studies are used.
Examples of Observational Studies
Selective Serotonin Reuptake Inhibitors and Violent Crime: A Cohort Study
A study published in PLOS magazine studied the uncertain relationship between SSRIs (like Prozac and Paxil) and Violent Crime. The researchers “…extracted information on SSRIs prescribed in Sweden between 2006 and 2009 from the Swedish Prescribed Drug Register and information on convictions for violent crimes for the same period from the Swedish national crime register. They then compared the rate of violent crime while individuals were prescribed SSRIs with the rate of violent crime in the same individuals while not receiving medication.” The study findings found an increased association between SSRI use and violent crimes.
Cleaner Air Found to Add 5 Months to Life
A Brigham Young University study examined the connected between air quality and life expectancy. The researchers looked at life expectancy data from 51 metropolitan areas and compared the figures to air quality improvements in each region from the 1980s to 1990s. After taking into account factors like smoking and socioeconomic status, the researchers found that an average of about five months life expectancy was attributed to clean air. The New York Times printed a summary of the results here.
Effects of Children of Occupational Exposures to Lead
Researchers matched 33 children whose parents were exposed to lead at work with 33 children who were the same age and loved in the same neighborhood. Elevated levels of lead were found in the exposed children. This was attributed to levels of lead that the parents were exposed to at work, and poor hygiene practices of the parent (UPenn).
Longitudinal Research
Longitudinal research is an observational study of the same variables over time. Studies can last weeks, months or even decades. The term “longitudinal” is very broad, but generally means to collect data over more than one period, from the same participants(or very similar participants). According to sociologist Scott Menard, Ph.D., the research should also involve some comparison of data among or between periods. However, the longitudinal research doesn’t necessarily have to be collected over time. Data could be collected at one point in time but include retrospective data. For example, a participant could be asked about their prior exercise habits up to and including the time of the study.
The purpose of Longitudinal Research is to:
- Record patterns of change. For example, the development of emphysema over time.
- Establish the direction and magnitude of causal relationships. For example, women who smoke are 12 times more likely to die of emphysema than non-smokers.
Cross Sectional Research
Cross sectional research involves collecting data at one specific point in time. You can interact with individuals directly, or you could study data in a database or other media. For example, you could study medical databases to see if illegal drug use results in heart disease. If you find a correlation (what is correlation?) between illegal drug use and heart disease, that would support the claim that illegal drug use may increase the risk of heart disease.
Cross sectional research is a descriptive study; you only record what you find and you don’t manipulate variables like in traditional experiments. It is most often used to look at how often a phenomenon occurs in a population.
Advantages and Disadvantages of Cross Sectional Research
Advantages
- Can be very inexpensive if you already have a database (for example, medical history data in a hospital database).
- Allows you to look at many factors at the same time, like age/weight/height/tobacco use/drug use.
Disadvantages
- Can result in weak evidence, compared to cohort studies (which cost more and take longer).
- Available data may not be suited to your research question. For example, if you wanted to know if sugar consumption leads to obesity, you are unlikely to find data on sugar consumption in a medical database.
- Cross sectional research studies are usually unable to control for confounding variables. One reason for this is that it’s usually difficult to find people who are similar enough. For example, they might be decades apart in age or they might be born in very different geographic regions.
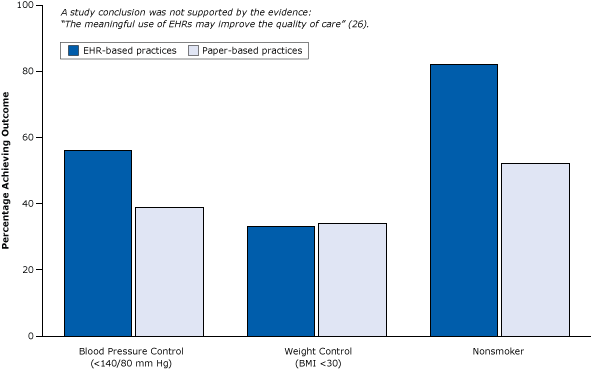
Cross sectional research can give the “big picture” and can be a foundation to suggest other areas for more expensive research. For example, if the data suggests that there may be a relationship between sugar consumption and obesity, this could bolster an application for funding more research in this area.
Cross-Sectional vs Longitudinal Research

Both cross-sectional and longitudinal research studies are observational. They are both conducted without any interference to the study participants. Cross-sectional research is conducted at a single point in time while a longitudinal study can be conducted over many years.
For example, let’s say researchers wanted to find out if older adults who gardened had lower blood pressure than older adults who did not garden. In a cross-sectional study, the researchers might select 100 people from different backgrounds, ask them about their gardening habits and measure their blood pressure. The study would be conducted at approximately the same period of time (say, over a week). In a longitudinal study, the questions and measurements would be the same. But the researchers would follow the participants over time. They may record the answers and measurements every year.
One major advantage of longitudinal research is that over time, researchers are more able to provide a cause-and-effect relationship. With the blood pressure example above, cross-sectional research wouldn’t give researchers information about what blood pressure readings were before the study. For example, participants may have had lower blood pressure before gardening. Longitudinal research can detect changes over time, both at the group and at the individual level.
Types of Longitudinal Design
Longitudinal Panel Design is the “traditional” type of longitudinal design, where the same data is collected from the same participants over a period of time. Repeated cross-sectional studies can be classified as longitudinal. Other types are:
- Total population design, where the total population is surveyed in each study period.
- Revolving panel design, where new participants are selected each period.
Pretest-Posttest Design.
What is Pretest Posttest Design?

A pretest posttest design is an experiment where measurements are taken both before and after a treatment. The design means that you are able to see the effects of some type of treatment on a group. Pretest posttest designs may be quasi-experimental, which means that participants are not assigned randomly. However, the most usual method is to randomly assign the participants to groups in order to control for confounding variables. Three main types of pretest post design are commonly used:
- Randomized Control-Group Pretest Posttest Design.
- Randomized Solomon Four-Group Design.
- Nonrandomized Control Group Pretest-Posttest Design.
1. Randomized Control-Group Pretest Posttest Design.
The pre-test post-test control group design is also called the classic controlled experimental design. The design includes both a control and a treatment group. For example, if you wanted to gauge if a new way of teaching math was effective, you could:
- Randomly assign participants to a treatment group or a control group.
- Administer a pre-test to the treatment group and the control group.
- Use the new teaching method on the treatment group and the standard method on the control group, ensuring that the method of treatment is the only condition that is different.
- Administer a post-test to both groups.
- Assess the differences between groups.
Two issues can affect the Randomized Control-Group Pretest Posttest Design:
- Internal validity issues: maturation (i.e. biological changes in participants can affect differences between pre- and post-tests) and history (where participants experience something outside of the treatment that can affect scores).
- External validity issues: Interaction of the pre-test and the treatment can occur if participants are influenced by the tone or content of the question. For example, a question about how many hours a student spends on homework might prompt the student to spend more time on homework.
2. Randomized Solomon Four-Group Design.
In this type of pretest posttest design, four groups are randomly assigned: two experimental groups E1/E2 and two control groups C1/C2. Groups E1 and C1 complete a pre-test and all four groups complete a post-test. This better controls for the interaction of pretesting and posttesting; in the “classic” design, participants may be unduly influenced by the questions on the pretest.
3. Nonrandomized Control Group Pretest-Posttest Design.
This type of test is similar to the “classic” design, but participants are not randomly assigned to groups. Nonrandomization can be more practical in real-life, when you are dealing with groups like students or employees who are already in classes or departments; randomization (i.e. moving people around to form new groups) could prove disruptive. This type of experimental design suffers from problems with internal validity more so than the other two types.
Back to Top.
Quasi-Experimental Design.

What is a Quasi-Experimental Design?
A quasi-experimental design has much the same components as a regular experiment, but is missing one or more key components. The three key components of a traditional experiment are:
- Pre-post test design.
- Treatment and control groups.
- Random assignment of subjects to groups.
You may want or need to deliberately leave out one of these key components. This could be for ethical or methodological reasons. For example:
- It would be unethical to withhold treatment from a control group. This is usually the case with life-threatening illness, like cancer.
- It would be unethical to treat patients; for example, you might want to find out if a certain drug causes blindness.
- A regular experiment might be expensive and impossible to fund.
- An experiment could technically fail due to loss of participants, but potentially produce useful data.
- It might be logistically impossible to control for all variables in a regular experiment.
These types of issues crop up frequently, leading to the widespread acceptance of quasi-experimental designs — especially in the social sciences. Quasi-experimental designs are generally regarded as unreliable and unscientific in the physical and biological sciences.
Some experiments naturally fall into groups. For example, you might want to compare educational experiences of first, middle and last born children. Random assignment isn’t possible, so these experiments are quasi-experimental by nature.
Quasi-Experimental Design Examples.
The general form of a quasi-experimental design thesis statement is “What effect does (a certain intervention or program) have on a (specific population)”?
Example 1 : Does smoking during pregnancy leads to low birth weight? It would be unethical to randomly assign one group of mothers packs of cigarettes to smoke. The researcher instead asks the mothers if they smoked during pregnancy and assigns them to groups after the fact.
Example 2 : Does thoughtfully designed software improve learning outcomes for students? This study used a pre-post test design and multiple classrooms to show how technology can be successfully implemented in schools.
Example 3 : Can being mentored for your job lead to increased job satisfaction? This study followed 73 employees, some who were mentored and some who were not.
Back to Top.
Randomized Block Design.
What is Randomized Block Design?
In randomized block design, the researcher divides experimental subjects into homogeneous blocks. Treatments are then randomly assigned to the blocks. The variability within blocks should be greater than the variability between blocks. In other words, you need to make sure that the blocks contain subjects that are very similar. For example, you could put males in one block and females in a second block. This method is practically identical to stratified random sampling(SRS), except the blocks in SRS are called “strata.” Randomized block design reduces variability in experiments.
For example, you might run an experiment to find out the efficacy of a new drug. According to the Merck Manual, one factor that can affect how a patient responds to a drug is age. Therefore, you run the risk that your results might be affected by age as a confounding variable. A Solution is to set up randomized block design so that different age groups are spread across equally sized blocks. The table below shows a randomized block design for a hypothetical experiment that tests a new drug on 1,000 people:
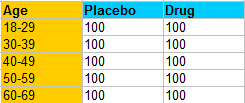
This randomized block design contains equal blocks of 200 people from each age group, where they are assigned randomly to either the placebo or the real drug. Therefore, age is removed as a potential source of variability.
Age isn’t the only potential source of variability. Other blocking factors that you could consider for this type of experiment include:
- Consumption of certain foods.
- Use of over the counter food supplements.
- Adherence to dosing regimen.
- Differences in metabolism due to genetic differences, liver or kidney issues, race, or sex.
- Coexistence of other disorders.
- Use of other drugs.
Randomized block experimental design is sometimes called randomized complete block experimental design, because the word “complete” makes it clear that all subjects are included in the experiment, not just a sample. However, the setup of the experiment usually makes it clear that all subjects are included, so most people will drop the word complete.
Back to Top.
Randomized Controlled Trial
What is a Randomized Controlled Trial?
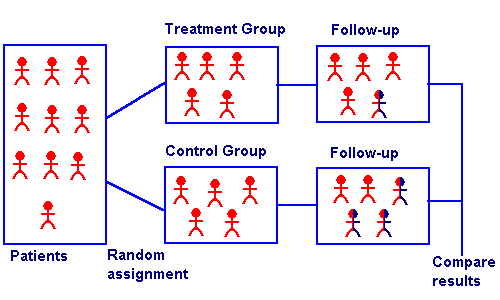
A randomized controlled trial is an experiment where the participants are randomly allocated to two or more groups to test a specific treatment or drug. Participants are assigned to either an experimental group or a comparison group. Random allocation means that all participants have the same chance of being placed in either group. The experimental group receives a treatment or intervention, for example:
- Diagnostic Tests.
- Experimental medication.
- Interventional procedures.
- Screening programs.
- Specific types of education.
Participants in the comparison group receive a placebo (a dummy treatment), an alternative treatment, or no treatment at all. There are many randomization methods available. For example, simple random sampling, stratified random sampling or systematic random sampling. The common factor for all methods is that researchers, patients and other parties cannot tell ahead of time who will be placed in which group.
Advantages and Disadvantages of Randomized Controlled Trials
Advantages
- Random allocation can cancel out population bias; it ensures that any other possible causes for the experimental results are split equally between groups.
- Blinding is easy to include in this type of experiment.
- Results from the experiment can be analyzed with statistical tests and used to infer other possibilities, like the likelihood of the method working for all populations.
- Participants are readily identifiable as members of a specific population./li>
Disadvantages
- Generally more expensive and more time consuming than other methods.
- Very large sample sizes (over 5,000 participants) are often needed.
- Random controlled trials cannot uncover causation/risk factors. For example, ethical concerns would prevent a randomized controlled trial investigating the risk factors for smoking.
- This type of experimental design is unsuitable for outcomes which take a long time to develop. Cohort studies may be a more suitable alternative.
- Some programs, for example cancer screening, are unsuited for random allocation of participants (again, due to ethical concerns).
- Volunteer bias can be an issue.
Within subjects Design.
What is a Within Subjects Experimental Design?
In a within subjects experimental design, participants are assigned more than one treatment: each participant experiences all the levels for any categorical explanatory variable. The levels can be ordered, like height or time. Or they can be un-ordered. For example, let’s say you are testing if blood pressure is raised when watching horror movies vs. romantic comedies. You could have all the participants watch a scary movie, then measure their blood pressure. Later, the same group of people watch a romantic comedy, and their blood pressure is measured.
Within subjects designs are frequently used in pre-test/post-test scenarios. For example, if a teacher wants to find out if a new classroom strategy is effective, they might test children before the strategy is in place and then after the strategy is in place.
Within subjects designs are similar to other analysis of variance designs, in that it’s possible to have a single independent variable, or multiple factorial independent variables. For example, three different depression inventories could be given at one, three, and six month intervals.
Advantages and Disadvantages of Within Subjects Experimental Design.
Advantages.
- It requires fewer participants than the between subjects design. If a between subjects design were used for the blood pressure example above, double the amount of participants would be required. Within subjects design therefore requires fewer resources and is generally cheaper.
- Individual difference between participants are controlled for, as each participant acts as their own control. As the subjects are measured multiple times, this better enables the researcher to hone in on individual differences so that they can be removed from the analysis.
Disadvantages.
- Effects from one test could carry over to the next, a phenomenon called the “range effect.” In the blood pressure example, if participants were asked to watch the scary movie first, their blood pressure could stay elevated for hours afterwards, skewing the results from the romantic comedy.
- Participants can exhibit “practice effects”, where they improve scores simply by taking the same test multiple times. This is often an issue on pre-test/post-test studies.
- Data is not completely independent, which may effect running hypothesis tests, like ANOVA.
References:
Merck Manual. Retrieved Jan 1, 2016 from: http://www.merckmanuals.com/professional/clinical-pharmacology/factors-affecting-response-to-drugs/introduction-to-factors-affecting-response-to-drugs
Penn State: Basic Principles of DOE. Retrieved Jan 1, 2016 from: https://onlinecourses.science.psu.edu/stat503/node/67
Image: SUNY Downstate. Retrieved Jan 1, 2016 from: http://library.downstate.edu/EBM2/2200.htm
5. Related Topics
- Accuracy and Precision.
- Block plots.
- Cluster Randomization.
- What is Clustering?
- What is the Cohort Effect?
- What is a Control Group?
- What is Counterbalancing?
- Data Collection Methods
- What is an Effect Size?
- What is a Experimental Group (or Treatment Group)?
- Fixed, Random, and Mixed Effects Models
- What are generalizability and transferability?
- What is Grounded Theory?
- The Hawthorne Effect.
- The Hazard Ratio.
- Inter-rater Reliability.
- Main Effects.
- Order Effects.
- The Placebo Effect
- What is the Practice Effect?
- Primary and Secondary Data.
- What is Qualitative Research?
- What is Quantitative Research?
- What is a Randomized Clinical Trial?
- Random Selection and Assignment.
- Randomization.
- Recall Bias.
- What is Response Bias?
- Research Methods (includes Quantitative and Qualitative).
- Subgroup Analysis.
- What is Survey Sampling?
- Systematic Errors.
- Treatment Diffusion.
References
Agresti A. (1990) Categorical Data Analysis. John Wiley and Sons, New York.
Cook, T. (2005). Introduction to Statistical Methods for Clinical Trials(Chapman & Hall/CRC Texts in Statistical Science) 1st Edition. Chapman and Hall/CRC
Friedman (2015). Fundamentals of Clinical Trials 5th ed. Springer.”
Dodge, Y. (2008). The Concise Encyclopedia of Statistics. Springer.
Everitt, B. S.; Skrondal, A. (2010), The Cambridge Dictionary of Statistics, Cambridge University Press.
Gonick, L. (1993). The Cartoon Guide to Statistics. HarperPerennial.
Kotz, S.; et al., eds. (2006), Encyclopedia of Statistical Sciences, Wiley.
Levine, D. (2014). Even You Can Learn Statistics and Analytics: An Easy to Understand Guide to Statistics and Analytics 3rd Edition. Pearson FT Press
UPenn. http://finzi.psych.upenn.edu/library/granovaGG/html/blood_lead.html. Retrieved May 1, 2020.