< List of probability distributions < Conjugate prior distribution
What is a conjugate prior distribution?
More specifically, a conjugate prior distribution (or just conjugate prior) is a prior distribution which — along with the data model — produces a posterior distribution that shares the same functional form as the prior distribution, but with new and updated parameter values [1]. In other words, if the prior distribution and the posterior distribution are members of the same parametric family, then the prior is a conjugate for the likelihood function.
Conjugate priors give us a closed-form expression for the posterior without having to deal with numerical integration. In other words, conjugate priors are useful because they reduce Bayesian updating to modifying parameters of the prior distribution (so-called hyperparameters) instead of calculating integrals [3]. In fact, the choice of prior given the likelihood function is often the only avenue to create an analytically tractable (i.e., solvable) solution to the integral [2]. Conjugate priors are also useful because it is typically easier to understand the respective contributions of the prior information and the data information to the posterior [1].
History of the conjugate prior distribution
Conjugate prior distributions were first discussed and formalized by Howard Raiffa and Robert Schlaifer in 1961 [4].
Bayes’ theorem is the foundation of Bayesian statistics. Though mathematically simple, its implementation can be challenging, mostly due to the difficulty of integrating the prior and likelihood functions over the domain of the parameter(s). This integration problem historically led to two approaches. Before computers, researchers focused on finding pairs of likelihood functions and prior distributions with convenient mathematical properties, which are conjugate or natural conjugate priors. Nowadays, computers can provide numerical approximations to the required integrals, but this is often computationally expensive and impractical on smaller computers [2].
Types of conjugate prior distribution
When choosing a family of conjugate prior distributions, we must specify a family that adequately describes your knowledge of the unknown parameter(s) before the experiment begins [2]. A conjugate prior family exists whenever there is a set of fixed-dimension sufficient statistics [4].
The beta distribution is a conjugate prior for the binomial, Bernoulli, and geometric likelihood functions. This means that if the likelihood function is binomial and the prior is a beta distribution then the posterior is also a beta distribution. In other words, if we use a beta distribution as the prior distribution for the probability of success in a binomial experiment, then the posterior distribution will also be a beta distribution.
All exponential distributions have conjugate priors. For example [5]:
- The conjugate prior for a normal distribution is a normal distribution.
- The conjugate prior for a multinomial distribution is a Dirichlet distribution.
Example: Showing gamma is a conjugate prior for a Poisson likelihood
The gamma distribution is a conjugate prior for a Poisson likelihood function. We can show this as follows:
The Poisson likelihood function is
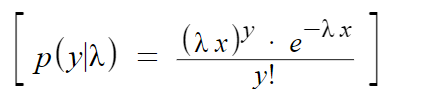
where
- y is the number of observed events (counts),
- λ is the parameter of the Poisson distribution,
- y! is the factorial of y.
The gamma probability density function (pdf) can be written in many different ways, but the most common way (which happens to be the easiest for showing the conjugate prior) is
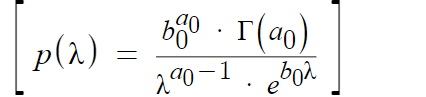
- a (or r) is the shape parameter,
- b (or v) is the scale parameter,
- λ is the rate parameter,
- Γ(r) is the gamma function.
The formula for a posterior distribution is prior * likelihood (assuming the marginal distribution is equal to 1), so, multiplying the Poisson likelihood and gamma distribution gives:
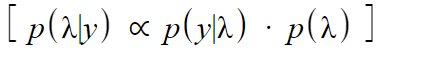
Simplification:
- We can ignore y! in the Poisson likelihood function because y! is a constant with respect to λ. This means that the likelihood function is proportional to ey e-λ.
- We can also ignore ab and Γ(a) in the gamma PDF because they are constants with respect to λ, which means that the gamma PDF is proportional to λb-1 e-bλ. Thus, we can simplify the formula to one where the gamma pdf becomes proportional to
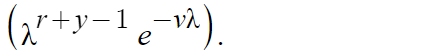
If you compare this solution with the formula for the gamma distribution, you should see that they look similar, except that a is now a + y and b is now b + 1. Thus, we can write:
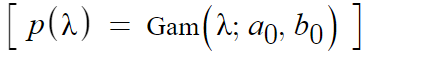
Formal definition of conjugate prior distribution
Let’s say we have data with likelihood function φ (x | θ), which depends on a hypothesized parameter θ. Let’s also say that the prior distribution for θ is one of a family of parametrized distributions fa(θ) (note: we’re not concerned with the the parameter names or how many there are). If the posterior distribution for θ is in this family—that is, if the posterior is fa′(θ). then the the family of priors are conjugate priors for the likelihood [3].
In simpler terms, this definition is saying that when we use a conjugate prior distribution, the posterior distribution that results from the Bayesian updating process is from the same parametric family as the prior.

References
[1] Hitchcok, D. STAT 535: Chapter 5: More Conjugate Priors. Retrieved August 20, 2023 from: https://people.stat.sc.edu/hitchcock/stat535slides5BRBhandout.pdf
[2] Fink, D. A Compendium of Conjugate Priors. Retrieved August 20, 2023 from: https://courses.physics.ucsd.edu/2018/Fall/physics210b/REFERENCES/conjugate_priors.pdf
[3] Orloff, J. & Bloom, J. Conjugate priors: Beta and normal. Retrieved August 20, 2023 from: https://math.mit.edu/~dav/05.dir/class15-prep.pdf
[4] Raiffa, Howard and Schlaifer, Robert. Applied Statistical Decision Theory, Division of Research, 1961 Graduate School of Business Administration, Harvard University, Boston
[5] Hockenmaier, J. Lecture 2: Conjugate priors. Retrieved August 20, 2023 from: https://courses.engr.illinois.edu/cs598jhm/sp2010/slides/lecture02ho.pdf