Bayesian Statistics and Probability > Prior distribution
What is a prior distribution?
A prior distribution, a key part of Bayesian inference, represents your belief about the true value of a parameter, in essence it is your “best guess.” It can be thought of as the process of assigning a prior probability distribution to a parameter, which represents your degree of belief concerning that parameter [1]. Formally, the new evidence is summarized with a likelihood function, so:
How Do I Create a Prior Distribution?
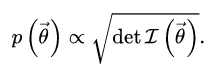
You could just take your best guess and sketch some kind of probability distribution (with a few descriptive parameters like the mean or the standard deviation).
If you don’t have any clue about what the distribution should look like, then you use what’s called an uninformative prior (or Jeffrey’s Prior). It’s exactly what is sounds like and is equivalent to picking a distribution out of a hat. Even if your model is completely unreasonable, once you’ve made some observations your posterior distribution will be an improvement over your initial guess. In fact, an uninformative distribution has very little effect on a posterior distribution, compared to a known prior.
More formally, those guesses at parameters are called hyperparameters— estimated parameters that do not involve observed data. Hyperparameters capture your prior beliefs, before data is observed [2].
Uninformative priors aren’t always necessary because many scientific fields have precise information about model parameters from previous medical studies, such as the parameter that best represents the liver as a fraction of body mass [3]. Thus, whether priors are uninformative or highly informative will largely depend on your field of study.
Calculating a prior distribution is the easy part. The stumbling block is turning that prior distribution into a posterior distribution. Incorporating prior beliefs into a probability distribution isn’t as easy as it sounds. One option is the Metropolis-Hastings algorithm, which can create an approximation for a posterior distribution (i.e. create a histogram) from the prior distribution and any observed samples.
Is there a true prior?
Whether or not a “true” prior distribution exists is up for debate. The traditional viewpoint is that the prior distribution represents a state of knowledge or a subjective state of mind, thus there cannot be a true prior by definition. A prior distribution can also be thought of as an expression of beliefs; as different people can have different beliefs, they will have different “true” priors. However, some statisticians disagree with this viewpoint, even going to far as the say that a true prior exists and has a frequentist interpretation [4].
According to Gelman [3], two benefits are gained by thinking of “true priors” instead of priors as a subjective choice:
-
- It establishes a link with frequentist statistics, which offers valuable insights into understanding statistical methods through their average properties. This connection allows us to leverage Bayesian methods effectively. While it is unreasonable to expect a procedure to yield the correct answer given the true unknown parameter value, aiming for accurate results by averaging over problems to which the model will be fitted is entirely reasonable.
- The connection to hierarchical models is noteworthy. In many scenarios, we can view a parameter of interest as part of a group or batch, as exemplified by the recent discussions on modeling multiple potential paths concurrently. In such cases, the true prior corresponds to the distribution of all the underlying effects in consideration.
References
- Chapter 5. Bayesian Statistics
- Riggelsen, C. (2008). Approximation Methods for Efficient Learning of Bayesian Networks. IOS Press.
- Gelman, A. (2002). Prior distribution. Wiley. Retrieved July 16, 2023 from: http://www.stat.columbia.edu/~gelman/research/published/p039-_o.pdf
- Geller, A. (2016). What is the “true prior distribution”? A hard-nosed answer. Retrieved July 16, 2023 from: https://statmodeling.stat.columbia.edu/2016/04/23/what-is-the-true-prior-distribution-a-hard-nosed-answer/