Estimators > Sufficient Statistic
Contents:
What is a sufficient statistic?
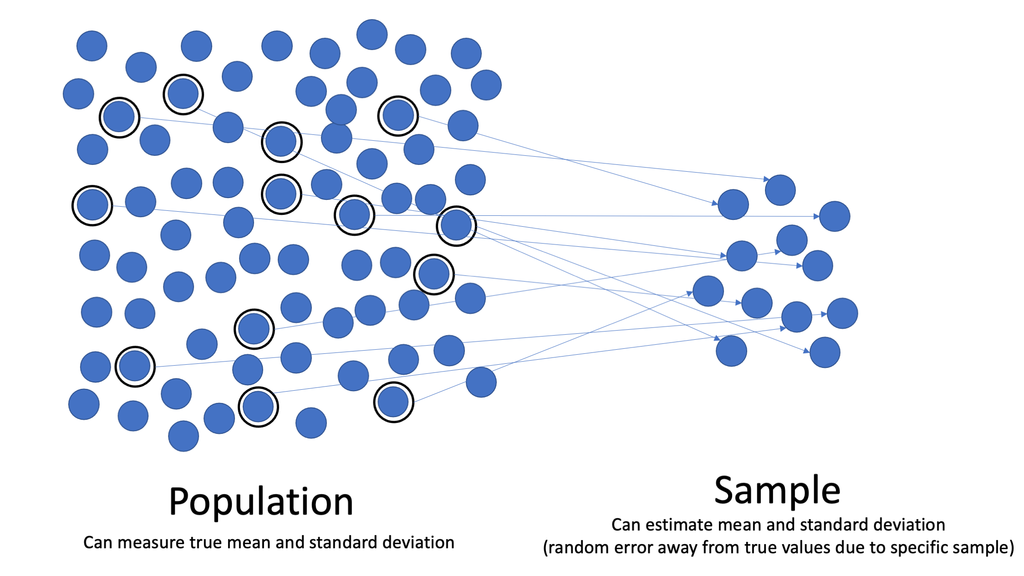
A sufficient statistic summarizes all of the information in a sample about a chosen parameter. For example, the sample mean, x̄, estimates the population mean, μ. x̄ is a sufficient statistic if it retains all of the information about the population mean that was contained in the original data points. According to statistician Ronald Fisher [2],
“…no other statistic that can be calculated from the same sample provides any additional information as to the value of the parameter.”
In layman’s terms, a sufficient statistic is your best bet for summarizing your data; You can use it even if you don’t know any of the actual values in the sample. Generally speaking, if something is sufficiently large, then it’s “big enough” for whatever purpose you’re using it for.
Sufficient statistic example
You can think of a sufficient statistic as an estimator that allows you to estimate the population parameter as well as if you knew all of the data in all possible samples.
For example, let’s say you have the simple data set 1,2,3,4,5.
- You would calculate the sample mean as (1 + 2 + 3 + 4 + 5) / 5 = 3, which gives you the estimate of the population mean as 3.
- Let’s assume you don’t know those values (1, 2, 3, 4, 5), but you only know that the sample mean is 3. You would also estimate the population mean as 3, which would be just as good as knowing the whole data set.
- The sample mean of 3 is a sufficient statistic.
- To put this another way, if you have the sample mean, then knowing all of the data items makes no difference in how good your estimate is: it’s already “the best”.
Order statistics for independent and identically distributed (iid) samples are also sufficient statistics. This does not hold for data that isn’t iid because only in these samples, can you re-order the data without losing meaning.
Back to TopFormal definition of sufficient statistics and the factorization theorem
More formally, a statistic Y is said to be a sufficient estimator for some parameter θ if the conditional distribution of Y: T(X1, X2,…,Xn) doesn’t depend on θ. While this definition appears to be fairly simple, actually finding the conditional distribution is the tough part. In fact, most statisticians consider it extremely difficult.
One slightly easier, way to find the conditional distribution is to use the Factorization Theorem: Suppose that you have a random sample X = (X1,…, Xn) from some function f(x|θ) and that f(x|θ) is the joint pdf of X. A statistic is sufficient if you can write the following joint pdf for functions g(t|θ) and h(x):
Where:
- θ is the unknown parameter belonging to the parameter space Q,
- and the pdf exists for all values of x, and θ ∈ Q.
Complement of sufficiency
An ancillary statistic is the complement of sufficiency. While sufficient statistics give you all of the information about a parameter, ancillary statistics give you no information.
Are sufficient statistics unbiased?
A sufficient statistic is not always unbiased.
“Unbiased” is not a requirement for sufficient statistics. For example, with a binomial distribution, the sample proportion is a sufficient statistic, but it’s not an unbiased estimator. The expected value of the sample proportion is only equal to the true value of the parameter when the sample size is infinite.
The main difference is that the unbiasedness of an estimator depends on the sampling distribution of the estimator, while the sufficiency of a statistic depends on the likelihood function of the data.
In some cases, a sufficient statistic could be unbiased because the sampling distribution of the statistic is centered at the parameter’s true value. For example, the sample mean for a normal distribution is a sufficient statistic and is also an unbiased estimator.
In other cases, a sufficient statistic might be biased because the sampling distribution of the statistic is not centered at the parameter’s true value. For example, the sample proportion of a binomial distribution is a sufficient statistic but not an unbiased estimator.
In general, there is no guarantee that a sufficient statistic will be unbiased.
Back to TopDo sufficient statistics always exist?
Sufficient statistics don’t always exist, and they are highly dependent on the model [3].
Some distributions do not have a sufficient statistic. For example, the uniform distribution on the interval [0,1] does not have a sufficient statistic. This is because any statistic that we define would be redundant, as all the information about the parameter is contained in the entire sample.
In other cases, a sufficient statistic may exist, but it might not be unique. Take the binomial distribution, for example, where both the sample proportion and sample mean serve as sufficient statistics.
There is no guarantee that a given distribution will have a sufficient statistic in general. However, if a sufficient statistic does exist, it can reduce the amount of data we need to collect without losing any relevant information about the parameter.
Back to TopHow do you prove something is not sufficient statistic?
To prove that a statistic is not sufficient:
- Identify the parameter you want to estimate with a statistic.
- Show that there is another statistic that contains more information about the parameter.
For example, let’s say you wanted to estimate the mean of a normal distribution with the variance. The sample variance is not a sufficient statistic for the mean of a normal distribution because there is another statistic — the sample mean — that has more information. The sample variance does not contain all the relevant information about the mean for making inferences about it. If we know the sample mean and the sample variance, we can learn more about the mean by knowing the entire sample.
Back to TopSufficient statistic vs MLE
Although similar, a sufficient statistic is not always a maximum likelihood estimator (MLE).
A sufficient statistic contains all the necessary information about the parameter for making inferences. An MLE maximizes the likelihood function based on sample data.
For example:
- The sample proportion is a sufficient statistic for a binomial distribution but the sample proportion is not an MLE.
- The sample mean is an MLE but not a sufficient statistic for the binomial distribution.
The MLE focuses on maximizing the likelihood function, while the sufficient statistic aims to summarize the relevant parameter information. In some cases, the MLE may lack relevant parameter information, making it an inefficient estimator. For example, the sample mean is an MLE for a normal distribution, but it is not a sufficient statistic. The sufficient statistic in this case includes both the sample mean and sample variance.
It is important to note that a sufficient statistic does not guarantee being an MLE. However, if a sufficient statistic is also an MLE, it is called a complete sufficient statistic.
Back to TopThe sufficiency principle
The Sufficiency Principle, S, (or Birnbaum’s S) allows us to potentially reduce our data footprint and eliminate extra, non-informative data. The data reduction method summarizes the data while retaining all the information about a particular parameter, θ.
Birnbaum [4] was first to outline the principle, which is defined as: “In the presence of a sufficient statistic t(x) with statistical model E’, the inferences concerning θ from E and x should be the same as from E’ and t(x)” ~ (Fraser, 1962 [5])
In other words, let’s say you have an observable variable x, with a model E. And let’s say you also have a sufficient statistic, t(x) with a model E. Any inferences about a certain parameter from the first model should be the same as those made from the second model. When collecting data, the sufficiency principle justifies ignoring certain pieces of information [6]. For example, let’s say you were conducting an experiment recording the number of heads in a coin toss. You could record the number of heads and tails, along with their order: HTTHTTTHHH…. Or, you could just record the number of heads (e.g. 25 heads). For the purposes of a binomial experiment, the number of heads would be a sufficient statistic. Recording all of the tails, and their order, would give you no more information (assuming the variables are independent and identically distributed).
Viewing the sufficiency principle as data reduction
We know from the sufficiency principle that if we have a sufficient statistic Y = T (X) and a statistical model, the inferences we can make about θ from our model and X (the data set) must be the same as from that model and Y. This makes sufficiency a very strong property; a way of data reduction, or condensing all the important information in our sample into the statistic.
The sufficiency principle unpacked
Let’s consider for moment Y, a sufficient statistic, and X, a set of observations. We want to look at the pair (X, Y). Since Y is dependent on X, the pair (X, Y) will give us the same information about parameter θ that X does. But since Y is sufficient, the conditional distribution of X given Y is independent of θ.
What exactly does that mean?
Let X be your last statistics lecture and the video recording of it, and Y be the notes you took about it. Parameter θ is information needed on question #7 in your class final. Y depends entirely on X, and the video and class notes includes exactly the same information as just the video did; nothing added. But if you’ve taken sufficient notes, the conditional distribution of the lecture given your notes is independent of that question #7 information.
Conditional distribution here just means the probability distribution of the info in your notes, given the lecture. If the info is in the lecture, it’s in your notes. Once you’ve checked your memorized notes, going back and listening to the lecture won’t help you solve question #7.
Now let’s go back to the generic sufficiency principle and mathematical statistics. A focus on both bits of information (data set X and statistic Y) does not give us any more information about the distribution of θ than we’d have if we only focused on the statistic. And after looking at statistic Y, a look at X doesn’t give us any new information on θ it won’t enlighten us on whether a particular value of θ is more likely or less likely then another. So if Y is a sufficient statistic, we don’t need to consider data set X any more, after using it to calculate Y; it becomes redundant.
Back to TopReferences
- Loneshieling, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
- Fisher, R.A. (1922). “On the mathematical foundations of theoretical statistics”. Philosophical Transactions of the Royal Society A 222: 309–368.
- Wolpert. R. STA 532: Theory of Statistical Inference
- Birnbaum, A. (1962). On the foundations of statistical inference. J. Am. Statist. Assoc. 57, 269-306.
- Fraser, D. (1962). On the Sufficiency and Likelihood Principles. Technical Report No. 43. Retrieved December 29, 2017 from: https://statistics.stanford.edu/sites/default/files/CHE%20ONR%2043.pdf
- Steel, D. (2007). Bayesian Confirmation Theory and the Likelihood Principle. Synthese 156: 53. Retrieved December 29, 2017 from: https://msu.edu/~steel/Bayes_and_LP.pdf