Probability and Statistics > Contents:
- What is Bayesian Statistics?
- Bayesian vs. Frequentist
- Important Concepts in Bayesian Statistics
- Related Articles
1. What is Bayesian Statistics?
Bayesian statistics, an alternative to “classical” statistics, involves conditional probabilities, or the probability of one event given that another event has already happened.
It is based on Bayes’ theorem and can be calculated using Bayes’ rule.
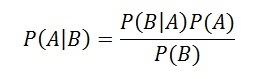
To apply the rule, start with background knowledge, called a prior. Then calculate posterior probabilities based on the prior and observational data in the form of a likelihood function. The prior probabilities, which are updated through an iterative data collection process, can help us answer questions such as
- Has this happened before?
- Is it probable, based on prior knowledge, that it will happen?
Bayesian statistics is named after English statistician Thomas Bayes (1701–1761).
Bayes’ Rule example
In a back pain clinic, 10% of patients receive narcotics as part of their pain prescription. Overall, 5% of the clinic’s patients are person’s addicted to narcotics, including both pain killers and illegal substances. Out of all the individuals prescribed pain pills, 8% are addicted to narcotics. If a patient is known to be addicted, what is the probability that they will be prescribed pain pills?
Solution:
- Determine the first event “A” based on the question. Ask yourself — which event comes first? This information is provided in the question. Event (A) is being prescribed pain pills, which is indicated as 10%.
- Determine event “B” based on the question. Event B refers to being an addict, which is stated as 5%.
- Calculate the probability of being an addict (Step 2) given that they are being prescribed pain pills (Step 1). In other words, determine what (B|A) is. We want to know “Given that people are prescribed pain pills, what is the probability that they are addicted?” The question indicates that it is 8%, or 0.8.
- Enter your answers into the formula and solve.
- P(A|B) = P(B|A) * P(A) / P(B) = (0.08 * 0.1) / 0.05 = 0.16
The probability that a person who is addicted will be prescribed pain pills is 0.16 (16%).
2. Bayesian vs. Frequentist
The opposite of Bayesian statistics is frequentist statistics —the type of statistics you study in an elementary statistics class. In elementary statistics, you use rigid formulas and probabilities. Bayesian probabilities are a lot more flexible. In a nutshell, frequentists use narrowly defined sets of formulas, tables, and solution steps. They are the grammar nazis of the probability world. On the other hand, Bayesian probability adds a few unknowns to the mix. The technical differences between the two approaches are not very intuitive, but this XKCD comic does a great job of summing them up:

3. Important Concepts in Bayesian Statistics
- Approximate Bayesian Computation (ABC): This set of techniques starts with a set of known summary statistics. A second set of the same statistics is calculated from a variety of potential models, and the candidates are placed in an acceptance/rejection loop. ABC favors those candidates that more closely match the known summary statistics [1].
- Admissible decision rule: A decision rule is a guideline to help you support or reject a null hypothesis. Generally, speaking, a decision rule is “admissible” if it is better than the set of all other possible decision rules. It’s similar to the line of best fit in regression analysis: it’s not a perfect fit, but it’s “good enough.”
- Bayesian efficiency: An efficient design requires you to input parameter values; In a Bayesian efficient model you have to take your “best guess” at what those parameters might be. Figuring out what is an efficient design (and what isn’t) by hand is only possible for very small designs, as it’s a computationally complex process [2].
- Bayes’ theorem is a way to figure out conditional probability. In a nutshell, it gives you the actual probability of an event given information about tests. For example, there is a test for cancer, and there is the event of actually having cancer.
- Bayes factor: the Bayes factor is a measure of relative likelihood between two hypotheses, or what Cornfield [3] calls the “relative betting odds.” The factor ranges between zero and infinity, where values close to zero are evidence against the null hypothesis and evidence for the alternate hypothesis [4].
- Bayesian network: A directed acyclic graph that represents a set of variables and their associated dependencies.
- Bayesian linear regression: treats regression coefficients and errors as random variables, instead of fixed unknowns. This tends to make the model more intuitive and flexible. However, the results are similar to simple linear regression if priors are uninformative and N is much greater than P (i.e. when the number of items is much greater than the number of prior distributions).
- Bayesian estimator: Also called a Bayes action, the Bayes estimator is defined as a minimizer of Bayes risk. In more general terms, it’s a single number that summarizes information found in a prior distribution about a particular parameter.
- Bayesian Information Criterion (also called the Schwarz criterion): given a set of models to choose from, you should choose the model with the lowest BIC.
- Bernstein–von Mises theorem: This is the Bayesian equivalent of the asymptotic normality results in the asymptotic theory of maximum likelihood estimation [5].
- Conjugate prior: A conjugate prior has the same distribution as your posterior prior. For example, if you’re studying people’s weights, which are normally distributed, you can use a normal distribution of weights as your conjugate prior.
- Credible interval: a range of values where an unobserved parameter falls with a certain subjective probability. It is the Bayesian equivalent of a confidence interval in frequentist statistics.
- Cromwell’s rule: This simple rule states that you should not assign probabilities of 0 (an event will not happen) or 1 (an event will happen), except when you can demonstrate an event is logically true or false. For example, the event 5 + 5 will logically add up to 10, so you can apply a probability of 1 to it.
- Empirical Bayes method: a technique where the prior distribution is estimated from actual data. This is unlike the usual Bayesian methods, where the prior distribution is fixed at the beginning of an experiment.
- Hyperparameter: a parameter from the prior distribution that’s set before the experiment begins.
- likelihood function A measurement of how well the data summarizes these parameters.
- Maximum a posteriori estimation: An estimate of an unknown; It is equal to the mode of the posterior distribution.
- Maximum entropy principle: This principle states that if you are estimating a probability distribution, you should select the distribution which gives you the maximum uncertainty (entropy).
- Posterior probability: Posterior probability is the probability an event will happen after all evidence or background information has been taken into account.
- Principle of indifference: states that if you have no reason to expect one event will happen over another, all events should be given the same probability.
Related Articles
- Bayesian Hypothesis Testing
- Fisher Information
- Inverse Probability
- Likelihood Function
- Posterior Distribution Probability
- Principle of Indifference.
References
- Medhi, K. (Ed.) (2014). Encyclopedia of Information Science and Technology, Third Edition. IGI Global.
- Hess, S. & Daly, A. (2010). Choice Modelling: The State-of-the-art and the State-of-practice – Proceedings from the Inaugural International Choice Modelling Conference. Emerald Group Publishing.
- Cornfield, J. Recent methodological contributions to clinical trials. Am J Epidemiol 1976; 104: 408–421. [PubMed] [Google Scholar]
- Spiegelhalter, D. et. al, (2004). Bayesian Approaches to Clinical Trials and Health-Care Evaluation. John Wiley and Sons.
- Ghosh, J. & Ramamoorthi, R. (2006). Bayesian Nonparametrics. Springer Science and Business Media.