Statistics Definitions > Fisher Information
What is Fisher information?
In statistics, Fisher information (or just information) measures information about a parameter in a distribution; the more “information” in X, the more accurate an estimator will be at estimating the parameter θ.
Fisher information measures how much information a random variable provides about an unknown parameter in a statistical model. Formally, it is defined as the variance of the score, where the score is the derivative of the log-likelihood function with respect to . When dealing with multiple parameters, these variances and covariances are captured in the Fisher information matrix.
Because Fisher information is essentially a variance, it is always non-negative and can be arbitrarily large (there is no upper bound). This reflects the fact that, in some cases, even small changes in the parameter can have a large impact on the likelihood function, which results in a large Fisher information value.
Finding the Fisher information
Finding the expected amount of information requires calculus. Specifically, a good understanding of integration techniques and partial derivatives is required if you want to derive information for a system.
Three different ways can calculate the amount of information contained in a random variable X:
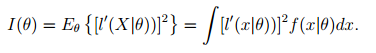
- This can be rewritten (if you change the order of integration and differentiation) as:
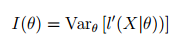
- Or, put another way:

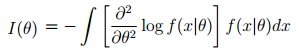
The bottom equation is usually the most practical. However, you may not have to use calculus, because expected information has been calculated for a wide number of distributions already. For example:
- Ly et.al [1] (and many others) state that the expected amount of information in a Bernoulli distribution is:
I(Θ) = 1 / Θ (1 – Θ). - For mixture distributions, trying to find information can “become quite difficult” [2]. If you have a mixture model, Wallis’s book Statistical and Inductive Inference by Minimum Message Length gives an excellent rundown on the problems you might expect.
If you’re trying to find expected information, try an Internet or scholarly database search first: the solution for many common distributions (and many uncommon ones) is probably out there.
Example
Find the fisher information for X ~ N(μ, σ2). The parameter, μ, is unknown.
Solution:
For −∞ < x < ∞:
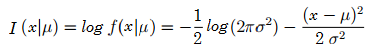
First and second derivatives are:
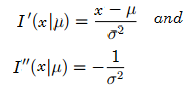
So the Fisher Information is:
![]()
Connection to the Cramér–Rao bound
The inverse of the Fisher information (or its matrix in the multiparameter case) sets a theoretical lower bound on the variance of any unbiased estimator of the parameter(s). This is often considered one of the most important applications of Fisher information.
The Cramér–Rao bound states that there is a fundamental limit on how precisely you can estimate a parameter from data, given the amount of information the data provide (as measured by Fisher information). In other words, no unbiased estimator can be more accurate than this bound allows. This limit shows why Fisher information is so important: the more Fisher information you have, the closer your estimator can come to this ultimate precision limit.
Fisher information uses
Uses include:
- Describing the asymptotic behavior of maximum likelihood estimates.
- Calculating the variance of an estimator.
- Finding priors in Bayesian inference.
Fisher information is used for slightly different purposes in Bayesian statistics and Minimum Description Length (MDL):
- Bayesian Statistics: finds a default prior for a parameter.
- Minimum description length (MDL): measures complexity for different models.
References
- Ly, A. et. al. A Tutorial on Fisher I. Retrieved September 8, 2016 from: http://www.ejwagenmakers.com/submitted/LyEtAlTutorial.pdf.
- Wallis, C. (2005). Statistical and Inductive Inference by Minimum Message Length. Springer Science and Business Media.