Probability Distributions > Pareto distribution
What is the Pareto Distribution?
The Pareto distribution is a skewed distribution with heavy, or “slowly decaying” tails (i.e. much of the data is in the tails).
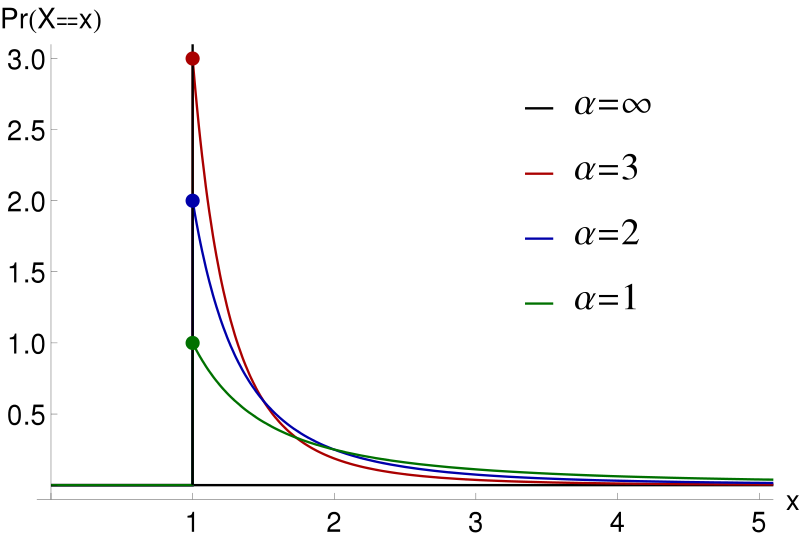
The Pareto distribution is defined by a shape parameter, α (also called a slope parameter or Pareto Index) and a location parameter, X. It has two main applications:
- To model the distribution of incomes.
- To model the distribution of city populations.
However, it can be used in a variety of other situations. For example, it can be used to model the lifetime of a manufactured item with a certain warranty period, sizes of human settlements and the size of oil reserves in oil fields [2].
Pareto distribution properties
The Pareto distribution probability density function (pdf) is expressed as [3]:
f(x) = α(βα) / xα+ 1
where:
-
- α > 0 = shape parameter; smaller values of α result in a heavier tail.
-
- β = scale parameter.
The PDF is a power of x, which leads to the name “power law.”
Note that there are many versions of the PDF in the literature, which can cause some confusion [4]:
Basically everyone writes α for the Pareto exponent, but for some people, that’s the exponent in the pdf, and for other people, that’s the exponent in the CCDF [survival function]. The two exponents always differ by exactly one, so this isn’t a big deal, but if you just want to borrow a formula, or compare empirical results, it’s annoying to have to constantly check which convention is being used by a particular author. ~ Cosma Shalizi, Associate Professor, Machine Learning Department, Carnegie Mellon University.
The cumulative distribution function (CDF) is often expressed as:
F(x) = 1 – (k/x)α
where:
- x is the random variable
- k is the lower bound of the data
- α is the shape parameter.
You might also see this written with λ as the minimum::
F(x) = 1 – (kλk/xk+1)α
When used to model income distribution, this particular version of the formula has λ as the minimum income and k as the distribution of income. The Pareto Distribution is characterized by heavy or “slowly decaying” tails. This means that much of the data falls in the extremes, creating an uneven distribution. The shape parameter (α) determines how heavily skewed the data will be, while the location parameter (X) determines where in the curve most of the values lie. In past studies, α values have ranged from 1 to 5 depending on what type of data is being analyzed.
The Survival Function
Most texts on the Pareto function refer to a survival function, also called a tail function or reliability function. This is the probability of values greater than the random variable X. For example, X = the proportion of household incomes greater than $100,000.
The survival function of the Pareto distribution is given by:
S(x) = 1 – (x/k)α
The survival function is also called the complementary cumulative distribution function (CCDF) or upper CDF [5].
Applications of the Pareto Distribution
As mentioned above, one of the major applications for this skewed distribution is to model income distributions. By studying income distributions, we can gain insight into wealth inequality between different countries or regions as well as track changes over time. This can help us better understand economic trends and develop effective policies to reduce inequality and poverty while promoting growth in certain areas.
Another application for this tool is to model city population distributions across different countries or regions. By studying population distributions, we can gain insight into population growth patterns over time as well as identify areas with higher or lower populations than expected given their geographic size. Again, this information can help us create more effective policies when it comes to migration and urbanization trends around the world.
The Pareto Principle
The Pareto Principle, derived from the Pareto distribution, is used to illustrate that many things are not distributed evenly. Originally written to state that 20% of the population holds 80% of the wealth, it can be applied more universally. For example, 1% of the population holds 99% of the wealth. However, it can be used to model any general situation where situations are not evenly distributed. For example, the top 20% of workers might produce 80% of output.

References
[1] Danvildanvil, CC BY-SA 3.0 <https://creativecommons.org/licenses/by-sa/3.0>, via Wikimedia Commons
[2] UCLA Statistics. AP Statistics Curriculum 2007 Pareto. Retrieved August 21, 2023 from: http://wiki.stat.ucla.edu/socr/index.php/AP_Statistics_Curriculum_2007_Pareto
[3] Jenkins, S. & van KErm, P. (2007). Fitting a Pareto (Type I) distribution by ML to unit record data. Retrieved August 21, 2023 from: http://fmwww.bc.edu/RePEc/bocode/p/paretofit.html
[4] Shalizi, C. (2021). Modeling Income and Wealth Distributions.