What is a Normalization Constant?
A normalizing constant ensures that a probability density function (pdf) has a probability of 1. The constant can take on various guises: it could be a scalar value, an equation, or even a function. As such, there isn’t a “one size fits all” constant; every probability distribution that doesn’t sum to 1 is going to have an individual normalization constant. The constant can take on different forms, such as a scalar value, an equation, or even a function. Thus, there isn’t a universal constant that applies to all probability distributions that do not sum to 1; each distribution has its own normalization constant. In many cases, the nonnormalized density function is known, but the normalization constant is not. In simple PDFs, the constant may be calculated relatively easy. In other cases, especially when the constant is a complicated function of the parameter space, it may be difficult or impossible to calculate. For example, the pdf of the normal distribution is known, but the normalization constant is not known in closed form. The normalization constant can be calculated numerically with the gamma function evaluated at σ2/2 + 1/2, but it is a complex function of the mean and variance of the distribution. However, the simplified version of the normalization constant , Z = √(2πσ2), [1] is often used in practice because it is easier to calculate. If you need to calculate a normalizing constant for a complex probability density function, consider using other numerical methods, such as importance sampling or Markov chain Monte Carlo.Polynomial normalizing constant
A polynomial normalizing constant ensures its value at 1 is 1, allowing the pdf to integrate to 1. Integration is the process of finding the area under a curve, which in this case is the pdf of the distribution. The area under the curve represents the probability that the random variable will take on a value within a certain range. For polynomials that evaluate to 1 at 1, the normalizing constant is simply 1. However, if the polynomial does not evaluate to 1 at 1, the normalizing constant will take on a different value. Calculating the normalizing constant involves dividing the polynomial by its integral. This process guarantees that the polynomial integrates to 1 and has a value of 1 at 1. The normalizing constant varies for each polynomial since it depends on the polynomial’s coefficients. Hence, polynomials with different coefficients will have different normalizing constants.Normalization Constant Examples
In a beta distribution, the function in the denominator of the pdf acts as a normalizing constant.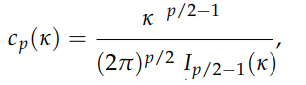
The normalizing constant in the Von Mises Fisher distribution, Pvmf(x; μ κ) := Cp(κ) e κμΤx is found by integrating polar coordinates. In the Kent distribution, the normalizing constant is an equation:
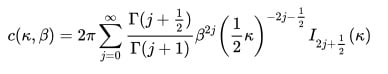 For Bayes’ rule, written as [2]:
For Bayes’ rule, written as [2]:
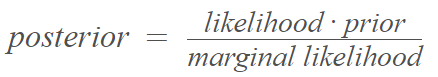
The denominator is the normalizing constant ensuring the posterior distribution adds up to 1; it can be calculated by summing the numerator over all possible values of the random variable. Calculation of the normalization becomes much more difficult for procedures like Bayes factor model selection or Bayesian model averaging; these are notoriously difficult to calculate and usually involve high dimensional integrals that are impossible to solve analytically [3].
Standardization vs Normalization
Both standardization and normalization are techniques used to transform data for easier analysis, but they do so in different ways:- Normalization transforms data to fall within a specific range. This is done by subtracting the minimum value from each data point and dividing by the difference between the minimum and maximum values. As noted above, you can also normalize to [0, 1] with a normalization constant.
- Standardization transforms data to have a mean of 0 and a standard deviation of 1. This is achieved by subtracting the mean from each data point and dividing by the standard deviation.
References
- The Gaussian distribution
- Murphy, K. In Symbols. Retrieved November 16, 2021 from: https://www.cs.ubc.ca/~murphyk/Bayes/bayesrule.html
- Gronau, Q. et al. bridgesampling: An R Package for Estimating Normalizing Constants. Retrieved November 16, 2021 from: https://cran.r-project.org/web/packages/bridgesampling/vignettes/bridgesampling_paper.pdf