Types of Functions > Likelihood function
What is a Likelihood Function?
Many probability distributions have unknown parameters; We estimate these unknowns using sample data. The Likelihood function gives us an idea of how well the data summarizes these parameters.
The “parameters” here are the parameters for a probability density function (pdf). In other words, they are the building blocks for a pdf, or what you need for parametrization. While the likelihood function measures the support given by data for each possible parameter value and gives us the most plausible value, it is not a pdf). Although a likelihood function might resemble a pdf, there is a fundamental difference: a pdf is a function of x, which represents a data point and informs the likelihood of certain data points occurring. On the other hand, a likelihood function takes a known dataset and represents the probability of different parameters for a distribution. T
he likelihood function can be thought of as the distribution of a random variable as a function of the parameter(s). Observed data values can be substituted in, which means we can then find the unknown parameter value that maximizes the likelihood function. The maximizing value is the one that makes the observed data most likely [1].
The likelihood function is more efficient than older and less sophisticated methods such as the method of moments and the method of minimum chi-square for count data. In addition, the likelihood has sampling distributions that can be solved with mathematical methods, older methods are mathematically intractable [2].
Simple Example
Let’s say you’re interested in creating a pdf that represents binomial probabilities for getting a heads (or tails) in a single coin toss. You’re going to estimate the likelihood of getting heads from your data, so you run an experiment. If you get two heads in a row, your likelihood function for the probability of a coin landing heads-up will look like this: 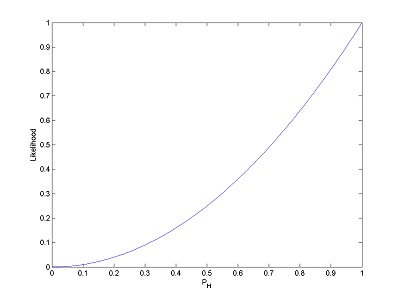
If you toss once more and get tails (making HHT), your function changes to look like this: 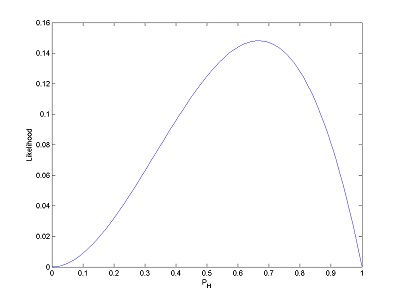 As a second example, suppose you wanted to know the whether a bag of mixed nuts originated in the United States or Australia. You know that mixed nuts sold in the United States have 50% peanuts compared to 30% in those sold in Australia — where almonds and native macadamias are more popular. In an experiment, a sample of five nuts were drawn from a random bag (missing the country of origin) and two peanuts were observed. We know that p is either 0.3 (an Australian bag) or 0.5 ( a United States bag). We need two calculations: one for p = 0.3 and one for p = 0.5.
As a second example, suppose you wanted to know the whether a bag of mixed nuts originated in the United States or Australia. You know that mixed nuts sold in the United States have 50% peanuts compared to 30% in those sold in Australia — where almonds and native macadamias are more popular. In an experiment, a sample of five nuts were drawn from a random bag (missing the country of origin) and two peanuts were observed. We know that p is either 0.3 (an Australian bag) or 0.5 ( a United States bag). We need two calculations: one for p = 0.3 and one for p = 0.5.
The likelihood function is:
- L(p|x) ∝p2 (1 − p)3 , p = 0.3 or 0.5.
- L(0.3|x) = 0.03087 < 0.03125 = L(0.5|x).
This suggests that it is more plausible that the bag was from the United States because that likelihood function is slightly larger at 0.03125. However, the difference in the likelihood functions is tiny, so it is difficult to say for sure which country the bag of nuts is from. A more definitive answer could be obtained by collecting more data.
Defining Likelihood Functions in Terms of Probability Density Functions
While a density function and a likelihood function are quite different, we can express on in terms of the other.
Suppose the joint probability density function of your sample X = (X1,…X2) is f(x| θ), where θ is a parameter. X = x is an observed sample point. Then the function of θ defined as L(θ |x) = f(x |θ) is your likelihood function.
Here it certainly looks like we’re just taking our pdf and cleverly relabeling it as a likelihood function. The reality, though, is actually quite different. For your pdf, you thought of θ as a constant and focused on an ever changing x. In the likelihood function, you let a sample point x be a constant and imagine θ to be varying over the whole range of possible parameter values.
When comparing two points on the probability density function, you examine two different values of x to determine which one is more likely to occur. However, with the likelihood function, you compare two different parameter points. For example, if L(θ1 | x) > L(θ2 | x), it indicates that the observed point x is more likely to have been observed under the parameter conditions θ = θ1 rather than θ = θ2.
Another important difference is how pdfs and likelihoods are normalized:
- A pdf is normalized so that the area under the curve equals 1.
- A likelihood function is not defined, although we can use the likelihood ratio to compare the likelihood of two possible sets of parameters [3].
Properties of Likelihoods
Unlike probability density functions, likelihoods aren’t normalized. The area under their curves does not have to add up to 1. In fact, we can only define a likelihood function up to a constant of proportionality. What that means that, rather than being one function, likelihood is an equivalence class of functions.
Using Likelihoods
Likelihoods are a key part of Bayesian inference. We also use likelihoods to generate estimators; we almost always want the maximum likelihood estimator.
References
- Hanley, J. Lecture notes on likelihood function. Retrieved July 16, 2023 from: http://www.medicine.mcgill.ca/epidemiology/hanley/bios601/Likelihood/Likelihood.pdf
- 1.5 – Maximum Likelihood Estimation
- Introduction to Likelihood Statistics.