Statistics Definitions > Interval Estimate
What is an Interval Estimate?
An interval estimate is a range of values for a parameter. For example, you might think that the mean of a data set falls somewhere between 10 and 100 (10 < μ < 100).
A related term is a point estimate, which is an exact value, like μ = 55. For example, a recent survey found that Americans eat an average of 20 pounds of ice cream every year. This is a point estimate and it represents a single value — in this case, 20 pounds. However, not every American eats 20 pounds of ice cream every year; some people might eat no ice cream, others might eat 100 pounds. This range, “somewhere between 0 and 100 pounds” is called an interval estimate.
Confidence Levels and Interval Estimates
There’s nothing wrong with making a good guess at an interval, but sometimes we want to be very confident that our results are reliable and replicable.
- “Reliable” means that your results are consistent and dependable: Repeating the testing process will give the same results.
- “Replicable” means that other people will be able to duplicate the experiment and get the same results, even under different conditions.
One way to achieve this is to express a confidence level. Confidence levels are percentages of certainty. For example, you might say you are 99% confident (i.e. you have a 99% confidence level) that between 5 and 15% of older citizens smoke cigarettes. When the interval estimate has a confidence level attached, it’s called a confidence interval.
- The lower bound (in this example, 5%) is called a lower confidence limit.
- The upper bound (in this example, 15%) is called an upper confidence limit.
But how confident are you that the range is from 5 to 15%? Are you 99% sure? 90% sure? Less? How you figure this is out is with probability theory: you want to find out the possibility that your results could be due to chance alone (as opposed to your results being repeatable).
Formula for determining interval estimate
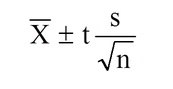
There are many ways to calculate interval estimates, depending on the type of data you have and the statistic you aim to estimate the interval for (e.g., the mean or proportion). For example, if you your sample data follows a t distribution, you can use t-scores to calculate an interval estimate.

Other ways to find confidence intervals include:
-
- For binary data — two values such as yes/no or true/false — can use the binomial distribution to calculate a confidence interval for the proportion.
-
- The confidence interval bootstrap is useful when you don’t know if your data follows a particular probability distribution. This non-parametric or “distribution free” method can help you calculate confidence intervals without any assumptions about the distribution of the population.
-
- The jackknife estimator is more conservative than the confidence interval bootstrap [2]. Its estimated standard error tends to be a little bit larger [3]. In practical terms, this means that it’s more likely the interval will contain the true value for the population parameter you’re estimating.
Each method has its advantages and disadvantages; which you use often boils down to a trade-off between Type I and Type II errors.
- A type I error is the error of rejecting the null hypothesis when it is true;
- A Type II error is the error of failing to reject the null hypothesis when it is false.
The big disadvantage of using a more conservative method, such as the jackknife, is that you are more likely to make a Type II error. Next: How to Find a Confidence Interval — The Easy Way!
References
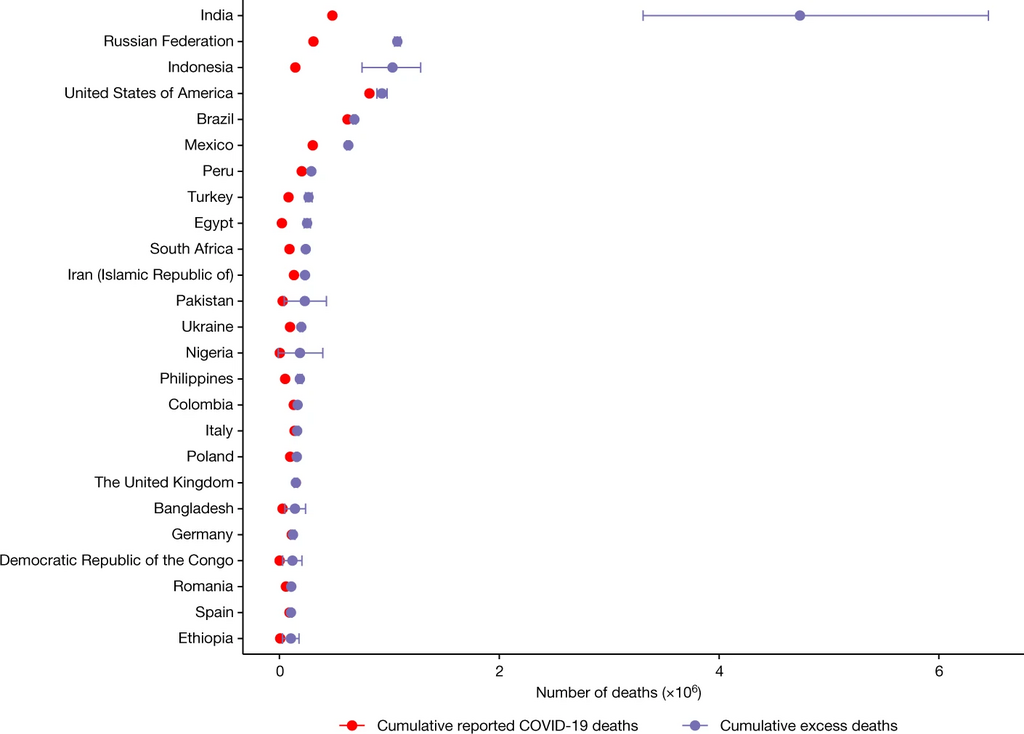
- Authors of the study: William Msemburi, Ariel Karlinsky, Victoria Knutson, Serge Aleshin-Guendel, Somnath Chatterji & Jon Wakefield, CC BY 4.0 https://creativecommons.org/licenses/by/4.0, via Wikimedia Commons
- Hanse, B. (2022). Jackknife Standard Errors for Clustered Regression
- The Bootstrap and Jackknife.