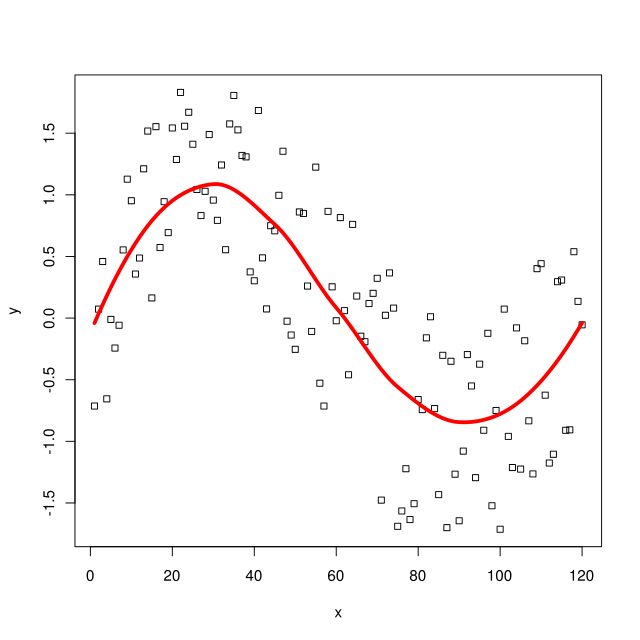
Statistical noise refers to the random irregularity present in real-life data. Noisy data lacks a discernible pattern, causing readings to fluctuate between being too small or too large. These errors are typically unpredictable and inevitable. The existence of noise implies that the outcomes of sampling may not be replicated if the process were repeated.
The term statistical noise was first used in the early 20th century by physicists to describe random fluctuations in physical quantities [2]. For example, the temperature of a gas fluctuates randomly, even if the gas is in a closed container. These random fluctuations are called statistical noise, a term later adopted in signal processing to refer to undesired electrical or electromagnetic energy that diminishes the quality of signals and data.
In machine learning, noisy data refers to data that is not machine readable. It includes unstructured text and any data that has been altered so that it is no longer compatible with the program used to create it. In density-based methods — points that are not part of a cluster are considered noise. When a data set contains more noise, such as overlapping target classes, SVM does not perform well. While K-means is sensitive to noise, the variant K-medoids clustering is more robust to noise [3].
Recognizing and quantifying the level of statistical noise in a dataset is crucial for analysis. It helps determine whether data shifts are statistically significant or merely part of random variation.
Quantifying Statistical Noise
Statistical noise generally consists of errors and residuals:
Errors might include measurement errors and sampling errors; the differences between the observed values we’ve actually measured and their ‘true values’. While most errors are unavoidable, systematic errors—can usually be avoided. They creep into your data when you make the same mistake over and over again. For example, let’s say you wanted to know something about the general health of the population, but only surveyed patients in doctors’ waiting rooms. That systematic error (polling sick people over and over again) will create a statistic that’s completely off the mark.
The residual of observed data is the difference between your observed value (again, that data point you’ve measured) and the predicted value; not the ‘true value’ per se but the point in space your theory tells you the data point should lie on. In regression analysis, it’s the distance between your observed data point and the regression line.
The standard deviation and variance are two ways to quantify statistical noise. The smaller the standard deviation and variance, the less noise present in the data.
Statistical noise is often referenced by margins of error. For instance, if polls tell us that candidate B has moved three percentage points up in public opinion, but the statistical noise (a.k.a. the margin of error) is 10 percentage points, we know that the change is not statistically significant.
How to avoid noise
It’s easy to introduce noise into data but it can be hard to detect. Exactly how you avoid noise depends on your field, but in general most errors cannot be avoided in statistical analysis. That said, the noise introduced by systematic errors is an exception — it can be prevented. Systematic errors occur when the same mistake is repeatedly made. For example, if you want to assess the general health of a population but only survey patients in doctors’ waiting rooms, this systematic error (repeatedly polling sick people) will result in skewed statistics. To avoid noise, eliminate systematic errors from your sampling method.
One method to proactively reduce noise is by using homogeneous samples [4]. For instance, in a clinical trial, you could include young, adult, drug-naïve patients who do not smoke, drink, or use other substances, do not have medical or psychiatric comorbidities, and have a baseline illness severity above a certain threshold. An advantage of having a sample that is clinically and sociodemographically homogeneous is that it may lead to more consistent outcomes compared to a diverse sample. However, a limitation is that the results obtained from such samples may not easily apply to the real world, where patients are typically heterogeneous.
Another way to avoid noise in research is to avoid using raw estimate results from a single, noisy study to estimate power [5]. Andrew Gelman, professor of statistics and political science at Columbia University, recommends that design and power analysis are performed using substantively-based effect size estimates [6]. Substantively-based effect size estimates are based on substantive knowledge of the phenomenon being studied. For example, if you are interested in the efficacy of a new flu drug consult with experts in the field of communicable diseases to get a sense of what a clinically meaningful effect size would be.
Chen-Pang Yeang; Two Mathematical Approaches to Random Fluctuations. Perspectives on Science 2016; 24 (1): 45–72. doi: https://doi.org/10.1162/POSC_a_00191
Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN COMPUT. SCI.2, 160 (2021). https://doi.org/10.1007/s42979-021-00592-x
Andrade C. Understanding Statistical Noise in Research: 1. Basic Concepts. Indian J Psychol Med. 2023 Jan;45(1):89-90. doi: 10.1177/02537176221139665. Epub 2022 Nov 22. PMID: 36778609; PMCID: PMC9896112.