Descriptive Statistics > Measures of Spread
What are Measures of Spread?
Measures of spread (also called measures of dispersion) tell you something about how wide the set of data is. There are several basic measures of spread used in statistics. The most common are:
- The range (including the interquartile range and the interdecile range),
- The standard deviation,
- The variance,
- Quartiles.
#1: The Range
 The range is the distance between the lowest and highest values in a data set. For example, if the smallest value is 10 and the largest 100, then the range is 90 (100 – 10). The range is a simple measure of spread, but it can be misleading if there are outliers in your data. For example, if you have a single point at x = 1000, but most of your data is between 0 and 100, then the range is 1000 (100 – 0), which is quite misleading. The interquartile range (IQR) is the “middle fifty” — the middle 50% of data. In other words, it tells you where the bulk of data lies. As this is a very useful fact to know for many data sets, it’s one of the most used measures of spread.
The range is the distance between the lowest and highest values in a data set. For example, if the smallest value is 10 and the largest 100, then the range is 90 (100 – 10). The range is a simple measure of spread, but it can be misleading if there are outliers in your data. For example, if you have a single point at x = 1000, but most of your data is between 0 and 100, then the range is 1000 (100 – 0), which is quite misleading. The interquartile range (IQR) is the “middle fifty” — the middle 50% of data. In other words, it tells you where the bulk of data lies. As this is a very useful fact to know for many data sets, it’s one of the most used measures of spread. 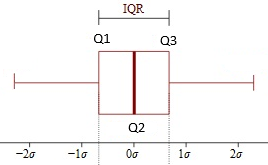
The interdecile range is similar to the IQR, except it tells us the center 80% of data, cutting off the top and bottom 10% of data.
A less common measure is the semi interquartile range, which is one half of the interquartile range.
![]()
#2: Standard Deviation
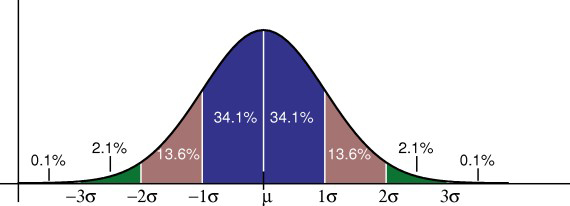
The standard deviation, represented by the Greek letter sigma (σ), shows how data is spread about the center of a distribution (e.g, the mean or median). It can give you an understanding of where a certain value falls percentage-wise. For example, if an exam follows a normal distribution and a test taker scores one standard deviation above the mean (show as (1σ in the above image) , that score falls in the top 84% of test takers. We know this because of the empirical rule, which tells use exactly where these percentages lie, although you could also add up the percentages leading up to the line at 1σ: 0.1% + 2.1% + 13.6% + 34.1% + 34.1% = 84%.
A related measure of spread is the coefficient of variation which tells us how spread out data is relative to the mean. It is defined as the standard deviation divided by the mean. 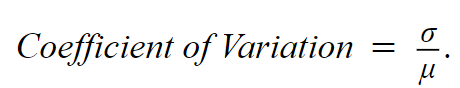 The Mean Absolute Deviation (MAD) is the average of the absolute differences between the data points and the mean. While this is certainly more complex to calculate than a regular arithmetic mean, it is one of the more robust measures of spread. “Robust” here means that the MAD — unlike the variance or standard deviation — tends not to be affected much by outliers.
The Mean Absolute Deviation (MAD) is the average of the absolute differences between the data points and the mean. While this is certainly more complex to calculate than a regular arithmetic mean, it is one of the more robust measures of spread. “Robust” here means that the MAD — unlike the variance or standard deviation — tends not to be affected much by outliers.
#3: The Variance
The variance gives you a very general idea of how spread out a data set is. But as a measure of spread, it’s somewhat limited. For example, a large variance of 22,000 doesn’t give much insight into the spread of data, other than indicating it’s large! However, variance can be used to calculate the standard deviation: defined as the square root of the variance. You can think of a standard deviation as a “standardized” or more useful type of variance.
#4: Quartiles

Quartiles split your data set into quarters based on where data point fall on the number line. It is similar to variance, in that quartiles aren’t very useful by themselves. Instead, they can be used to calculate more helpful values such as the interquartile range.
Which measures of spread should I use?
Some considerations when deciding which measure of spread to apply to your analysis:
- If your data set includes outliers, consider using a robust measure of spread such as the median absolute deviation (MAD).
- If your data is on an wide ranging scale, consider a measure of spread that tends to remain unaffected by scale, such as the coefficient of variation (CV).
- If you’re only interested in the general spread of data, a measure like the standard deviation (SD) might be suitable. However, if you’re more concerned with the spread of the central 50% of the data, the IQR would be a better choice.
A note on scale parameters as measures of spread
Although not typically thought of as a measure of spread, scale parameters are set for probability distributions to control the spread of values in a distribution.
- Larger scale parameters tend to widen, or flatten, a probability distribution.
- Smaller scale parameters will shrink or narrow a distribution.