Probability and Statistics > Regression Analysis > Logistic Regression / Logit Model In order to understand logistic regression (also called the logit model), you may find it helpful to review these topics:
What is logistic regression?
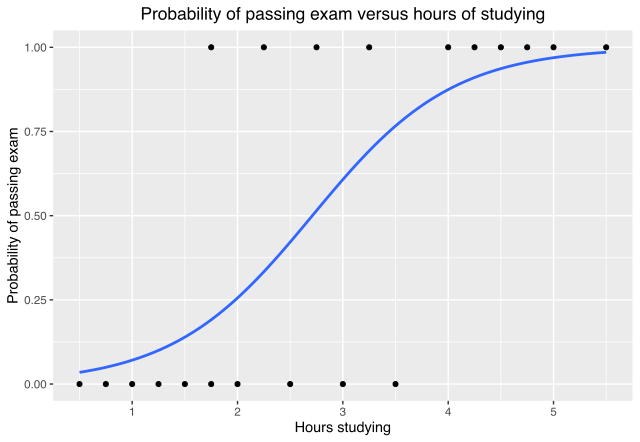
Logistic regression, also called the logit model, estimates the probability of event occurring based on given data. This S-shaped distribution is similar to the standard normal distribution, but the probabilities are easier to calculate [2].
Logistic regression is often used to predict the probability of a binary outcome (e.g., yes/no, pass/fail, etc.), given a single measurement variable (e.g., height, weight, etc.). Logistic regression can also be applied to ordinal data — variables with more than two ordered categories, such as survey data — but this is not common. This type of regression is especially useful for classification problems, where you are trying to determine if new data fits best into a category. For example, in cyber security, logistic regression is useful in binary classification problems, such as detecting threats, where there are only two classes (threat, or not a threat) [3]. In natural language processing, this method is the baseline supervised machine learning algorithm for classification [4].
The logistic regression model is a non-linear transformation of linear regression. More specifically, it is a transformation of log p with an unbounded range. Logistic regression predicts probabilities rather than placing data neatly into classes. In other words, it estimates the probability of belonging to a certain category, given a set of predictor variables. The decision boundary is the solution of β0 + x · β = 0 and separates the two predicted classes.
Types of logistic regression
Simple logistic regression is almost identical to linear regression. However, linear regression uses two measurements and logistic regression uses one measurement and one nominal variable. The measurement variable is always the independent variable. It’s used when you want to find the probability of getting a certain nominal variable when you have a particular measurement variable.
There are various subtypes of logistic regression. Which type you choose depends on the nature of the categorical response variable [5]:
- With linear regression, predicted values will become greater than one and less than zero if you move far enough on the x-axis. As probabilities can only range from 0 to 1, this is nonsensical and can lead to issue when predicted values are used in subsequent analysis. Logistic regression does not have this issue.
- One of the assumptions of regression is homoscedasticity — the variance of the dependent variable is constant across all values of the independent variable. This assumption doesn’t hold for binary variables, because the variance for binary variables is PQ; the maximum variance is .25 when 50 percent of the data are 1s. The variance decreases as you move toward more extreme values. For example, when P =.10, the variance is .1*.9 = .09, so as P approaches 1 or zero, the variance approaches zero.
- Significance testing of the logistic regression coefficient weights assumes that prediction errors (Y – Y’) are normally distributed. Because the dependent variable Y only takes the values 0 and 1, this assumption is difficult to justify. Therefore, tests of regression weights are suspect if you use linear regression with a binary dependent variable [6].
Comparison with Discriminant Analysis
Discriminant analysis is a classification method that gets its name from discriminating — the act of recognizing a difference between certain characteristics. The two goals are:
- Construction of a classification method to separate members of a population.
- Using the classification method to allocate new members to groups within the population.
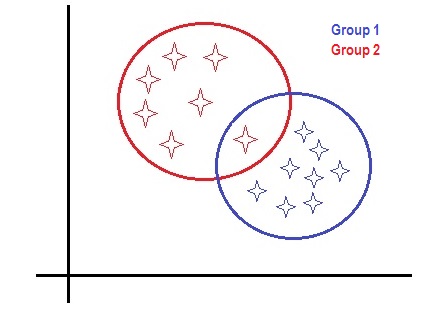 Discriminant Analysis is used when you have a set of naturally formed groups and you want to find out which continuous variables discriminate between them. The simplest example of DA is to use a single variable to predict where a member will fall in a population. For example, using high school GPA to predict whether a student will drop out of college, graduate from college, or graduate with honors. A more complex example: you might want to find out which variables discriminate between credit applicants who are a high, medium, or low risk for default. You could collect data on credit card holder characteristics and use that information to determine what variables are the best predictors for whether a particular person will be a high, medium, or low risk. New observations (in this case, new applicants) could then be allocated to a particular group. As well as the credit and banking industries, other uses for Discriminant Analysis include:
Discriminant Analysis is used when you have a set of naturally formed groups and you want to find out which continuous variables discriminate between them. The simplest example of DA is to use a single variable to predict where a member will fall in a population. For example, using high school GPA to predict whether a student will drop out of college, graduate from college, or graduate with honors. A more complex example: you might want to find out which variables discriminate between credit applicants who are a high, medium, or low risk for default. You could collect data on credit card holder characteristics and use that information to determine what variables are the best predictors for whether a particular person will be a high, medium, or low risk. New observations (in this case, new applicants) could then be allocated to a particular group. As well as the credit and banking industries, other uses for Discriminant Analysis include:
- Developing facial recognition technology.
- Classifying biological species.
- Classifying tumors.
- Determining the best candidates for college admissions.
Logistic Regression is often preferred over Discriminant Analysis as it can handle categorical variables and continuous variables. Logistic Regression also does not have as many assumptions associated with it. For example, Discriminant Analysis requires the assumptions of equal variance-covariance within each group, multivariate normality, and the data must be linearly related. Logistic Regression does not have these requirements.
References
[1] Canley, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
[2] An Introduction to Logistic Regression. Retrieved October 27, 2023 from: https://www.appstate.edu/~whiteheadjc/service/logit/intro.htm
[3] Edgar, R. & Manz, O. (2017). Exploratory Study. Research Methods for Cyber Security.
[4] Logistic Regression. Retrieved October 27, 2023 from: http://faculty.cas.usf.edu/mbrannick/regression/Logistic.html
[5] Penn State. Logistic regression. Retrieved October 28, 2023 from: https://online.stat.psu.edu/stat462/node/207/
[6] Jurafsky, D. & Martin, J. (2023). Speech and Language Processing. Draft. Retrieved October 27, 2023 from: https://web.stanford.edu/~jurafsky/slp3/5.pdf
Related Articles
Hosmer-Lemeshow Goodness of Fit test. What are Log Odds? Check out our YouTube channel for hundreds of videos on elementary statistics and probability.
- Nominal logistic regression is used for three or more categories with no natural ordering to levels. Examples of nominal responses include business departments (e.g., HR, IT, Sales), type of degree sought (e.g., computer science, math, English), and hair color (black, brown, red).
- Ordinal Logistic Regression is used when there are three or more categories with a natural ordering to the levels, but the ranking of the levels doesn’t have to have equal intervals. For example, ordinal responses could be how employees rate their manager’s effectiveness (e.g., good, fair, poor), or levels of flavors for hot sauces.
Logistic Regression, ANOVA and Student’s T-Tests
A one-way ANOVA or Student’s t-test can be used to compare the means of two groups on a measurement variable, when groups are defined by a nominal variable. In comparison, logistic regression is used to predict the probability of a binary outcome (e.g., whether or not a person has a heart attack) given a measurement variable (e.g., BMI). That’s not to say that you can’t use all three with the same data; the difference is in what types of questions you want answered.
For example, suppose you want to investigate the relationship between BMI and heart attack risk in 60-year-old women:
- Is BMI is associated with heart attack risk? Use a one-way ANOVA to test the hypothesis that there is no difference in mean BMI between women who have had a heart attack and those who have not.
- Is the difference in mean BMI between the two groups statistically significant? Use a Student’s t-test to compare the mean BMIs of the two groups.
- Which women are at high risk of heart attack? Use logistic regression to predict the probability of a woman of a certain age having a heart attack in the next decade, given her BMI.
In general, logistic regression is more powerful than ANOVA or t-tests for predicting binary outcomes. However, ANOVA and t-tests can be useful for understanding the relationship between a measurement variable and a nominal variable, even if the relationship is not strong enough to be statistically significant in a logistic regression model.
Logistic Regression vs. Linear Regression
In linear regression, you must have two measurements (x and y). In logistic regression, your dependent variable (your y variable) is nominal. In the above example, your y variable could be “had a myocardial infarction” vs. “did not have a myocardial infarction.” However, you can’t plot those nominal variables on a graph, so what you do is plot the probability of each variable (from 0 to 1). For example, your study might show that a woman with a BMI of 30 has a 4% chance of having a heart attack within the next ten years; you could plot that as 30 for the X variable and 0.04 for the Y variable.
Why not use ordinary linear regression?
- With linear regression, predicted values will become greater than one and less than zero if you move far enough on the x-axis. As probabilities can only range from 0 to 1, this is nonsensical and can lead to issue when predicted values are used in subsequent analysis. Logistic regression does not have this issue.
- One of the assumptions of regression is homoscedasticity — the variance of the dependent variable is constant across all values of the independent variable. This assumption doesn’t hold for binary variables, because the variance for binary variables is PQ; the maximum variance is .25 when 50 percent of the data are 1s. The variance decreases as you move toward more extreme values. For example, when P =.10, the variance is .1*.9 = .09, so as P approaches 1 or zero, the variance approaches zero.
- Significance testing of the logistic regression coefficient weights assumes that prediction errors (Y – Y’) are normally distributed. Because the dependent variable Y only takes the values 0 and 1, this assumption is difficult to justify. Therefore, tests of regression weights are suspect if you use linear regression with a binary dependent variable [6].
Comparison with Discriminant Analysis
Discriminant analysis is a classification method that gets its name from discriminating — the act of recognizing a difference between certain characteristics. The two goals are:
- Construction of a classification method to separate members of a population.
- Using the classification method to allocate new members to groups within the population.
Discriminant Analysis is used when you have a set of naturally formed groups and you want to find out which continuous variables discriminate between them. The simplest example of DA is to use a single variable to predict where a member will fall in a population. For example, using high school GPA to predict whether a student will drop out of college, graduate from college, or graduate with honors. A more complex example: you might want to find out which variables discriminate between credit applicants who are a high, medium, or low risk for default. You could collect data on credit card holder characteristics and use that information to determine what variables are the best predictors for whether a particular person will be a high, medium, or low risk. New observations (in this case, new applicants) could then be allocated to a particular group. As well as the credit and banking industries, other uses for Discriminant Analysis include:
- Developing facial recognition technology.
- Classifying biological species.
- Classifying tumors.
- Determining the best candidates for college admissions.
Logistic Regression is often preferred over Discriminant Analysis as it can handle categorical variables and continuous variables. Logistic Regression also does not have as many assumptions associated with it. For example, Discriminant Analysis requires the assumptions of equal variance-covariance within each group, multivariate normality, and the data must be linearly related. Logistic Regression does not have these requirements.
References
[1] Canley, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
[2] An Introduction to Logistic Regression. Retrieved October 27, 2023 from: https://www.appstate.edu/~whiteheadjc/service/logit/intro.htm
[3] Edgar, R. & Manz, O. (2017). Exploratory Study. Research Methods for Cyber Security.
[4] Logistic Regression. Retrieved October 27, 2023 from: http://faculty.cas.usf.edu/mbrannick/regression/Logistic.html
[5] Penn State. Logistic regression. Retrieved October 28, 2023 from: https://online.stat.psu.edu/stat462/node/207/
[6] Jurafsky, D. & Martin, J. (2023). Speech and Language Processing. Draft. Retrieved October 27, 2023 from: https://web.stanford.edu/~jurafsky/slp3/5.pdf
Related Articles
Hosmer-Lemeshow Goodness of Fit test. What are Log Odds? Check out our YouTube channel for hundreds of videos on elementary statistics and probability.
- Nominal logistic regression is used for three or more categories with no natural ordering to levels. Examples of nominal responses include business departments (e.g., HR, IT, Sales), type of degree sought (e.g., computer science, math, English), and hair color (black, brown, red).
- Ordinal Logistic Regression is used when there are three or more categories with a natural ordering to the levels, but the ranking of the levels doesn’t have to have equal intervals. For example, ordinal responses could be how employees rate their manager’s effectiveness (e.g., good, fair, poor), or levels of flavors for hot sauces.
Logistic Regression, ANOVA and Student’s T-Tests
A one-way ANOVA or Student’s t-test can be used to compare the means of two groups on a measurement variable, when groups are defined by a nominal variable. In comparison, logistic regression is used to predict the probability of a binary outcome (e.g., whether or not a person has a heart attack) given a measurement variable (e.g., BMI). That’s not to say that you can’t use all three with the same data; the difference is in what types of questions you want answered.
For example, suppose you want to investigate the relationship between BMI and heart attack risk in 60-year-old women:
- Is BMI is associated with heart attack risk? Use a one-way ANOVA to test the hypothesis that there is no difference in mean BMI between women who have had a heart attack and those who have not.
- Is the difference in mean BMI between the two groups statistically significant? Use a Student’s t-test to compare the mean BMIs of the two groups.
- Which women are at high risk of heart attack? Use logistic regression to predict the probability of a woman of a certain age having a heart attack in the next decade, given her BMI.
In general, logistic regression is more powerful than ANOVA or t-tests for predicting binary outcomes. However, ANOVA and t-tests can be useful for understanding the relationship between a measurement variable and a nominal variable, even if the relationship is not strong enough to be statistically significant in a logistic regression model.
Logistic Regression vs. Linear Regression
In linear regression, you must have two measurements (x and y). In logistic regression, your dependent variable (your y variable) is nominal. In the above example, your y variable could be “had a myocardial infarction” vs. “did not have a myocardial infarction.” However, you can’t plot those nominal variables on a graph, so what you do is plot the probability of each variable (from 0 to 1). For example, your study might show that a woman with a BMI of 30 has a 4% chance of having a heart attack within the next ten years; you could plot that as 30 for the X variable and 0.04 for the Y variable.
Why not use ordinary linear regression?
- With linear regression, predicted values will become greater than one and less than zero if you move far enough on the x-axis. As probabilities can only range from 0 to 1, this is nonsensical and can lead to issue when predicted values are used in subsequent analysis. Logistic regression does not have this issue.
- One of the assumptions of regression is homoscedasticity — the variance of the dependent variable is constant across all values of the independent variable. This assumption doesn’t hold for binary variables, because the variance for binary variables is PQ; the maximum variance is .25 when 50 percent of the data are 1s. The variance decreases as you move toward more extreme values. For example, when P =.10, the variance is .1*.9 = .09, so as P approaches 1 or zero, the variance approaches zero.
- Significance testing of the logistic regression coefficient weights assumes that prediction errors (Y – Y’) are normally distributed. Because the dependent variable Y only takes the values 0 and 1, this assumption is difficult to justify. Therefore, tests of regression weights are suspect if you use linear regression with a binary dependent variable [6].
Comparison with Discriminant Analysis
Discriminant analysis is a classification method that gets its name from discriminating — the act of recognizing a difference between certain characteristics. The two goals are:
- Construction of a classification method to separate members of a population.
- Using the classification method to allocate new members to groups within the population.
Discriminant Analysis is used when you have a set of naturally formed groups and you want to find out which continuous variables discriminate between them. The simplest example of DA is to use a single variable to predict where a member will fall in a population. For example, using high school GPA to predict whether a student will drop out of college, graduate from college, or graduate with honors. A more complex example: you might want to find out which variables discriminate between credit applicants who are a high, medium, or low risk for default. You could collect data on credit card holder characteristics and use that information to determine what variables are the best predictors for whether a particular person will be a high, medium, or low risk. New observations (in this case, new applicants) could then be allocated to a particular group. As well as the credit and banking industries, other uses for Discriminant Analysis include:
- Developing facial recognition technology.
- Classifying biological species.
- Classifying tumors.
- Determining the best candidates for college admissions.
Logistic Regression is often preferred over Discriminant Analysis as it can handle categorical variables and continuous variables. Logistic Regression also does not have as many assumptions associated with it. For example, Discriminant Analysis requires the assumptions of equal variance-covariance within each group, multivariate normality, and the data must be linearly related. Logistic Regression does not have these requirements.
References
[1] Canley, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
[2] An Introduction to Logistic Regression. Retrieved October 27, 2023 from: https://www.appstate.edu/~whiteheadjc/service/logit/intro.htm
[3] Edgar, R. & Manz, O. (2017). Exploratory Study. Research Methods for Cyber Security.
[4] Logistic Regression. Retrieved October 27, 2023 from: http://faculty.cas.usf.edu/mbrannick/regression/Logistic.html
[5] Penn State. Logistic regression. Retrieved October 28, 2023 from: https://online.stat.psu.edu/stat462/node/207/
[6] Jurafsky, D. & Martin, J. (2023). Speech and Language Processing. Draft. Retrieved October 27, 2023 from: https://web.stanford.edu/~jurafsky/slp3/5.pdf
Related Articles
Hosmer-Lemeshow Goodness of Fit test. What are Log Odds? Check out our YouTube channel for hundreds of videos on elementary statistics and probability.
- Binary logistic regression predicts the probability of an outcome with two possible values, such as passing or failing a test, responding yes or no to a survey, or having high or low blood pressure.
- Multinomial logistic regression can model scenarios with more than two possible discrete outcomes:
- Nominal logistic regression is used for three or more categories with no natural ordering to levels. Examples of nominal responses include business departments (e.g., HR, IT, Sales), type of degree sought (e.g., computer science, math, English), and hair color (black, brown, red).
- Ordinal Logistic Regression is used when there are three or more categories with a natural ordering to the levels, but the ranking of the levels doesn’t have to have equal intervals. For example, ordinal responses could be how employees rate their manager’s effectiveness (e.g., good, fair, poor), or levels of flavors for hot sauces.
Logistic Regression, ANOVA and Student’s T-Tests
A one-way ANOVA or Student’s t-test can be used to compare the means of two groups on a measurement variable, when groups are defined by a nominal variable. In comparison, logistic regression is used to predict the probability of a binary outcome (e.g., whether or not a person has a heart attack) given a measurement variable (e.g., BMI). That’s not to say that you can’t use all three with the same data; the difference is in what types of questions you want answered.
For example, suppose you want to investigate the relationship between BMI and heart attack risk in 60-year-old women:
- Is BMI is associated with heart attack risk? Use a one-way ANOVA to test the hypothesis that there is no difference in mean BMI between women who have had a heart attack and those who have not.
- Is the difference in mean BMI between the two groups statistically significant? Use a Student’s t-test to compare the mean BMIs of the two groups.
- Which women are at high risk of heart attack? Use logistic regression to predict the probability of a woman of a certain age having a heart attack in the next decade, given her BMI.
In general, logistic regression is more powerful than ANOVA or t-tests for predicting binary outcomes. However, ANOVA and t-tests can be useful for understanding the relationship between a measurement variable and a nominal variable, even if the relationship is not strong enough to be statistically significant in a logistic regression model.
Logistic Regression vs. Linear Regression
In linear regression, you must have two measurements (x and y). In logistic regression, your dependent variable (your y variable) is nominal. In the above example, your y variable could be “had a myocardial infarction” vs. “did not have a myocardial infarction.” However, you can’t plot those nominal variables on a graph, so what you do is plot the probability of each variable (from 0 to 1). For example, your study might show that a woman with a BMI of 30 has a 4% chance of having a heart attack within the next ten years; you could plot that as 30 for the X variable and 0.04 for the Y variable.
Why not use ordinary linear regression?
- With linear regression, predicted values will become greater than one and less than zero if you move far enough on the x-axis. As probabilities can only range from 0 to 1, this is nonsensical and can lead to issue when predicted values are used in subsequent analysis. Logistic regression does not have this issue.
- One of the assumptions of regression is homoscedasticity — the variance of the dependent variable is constant across all values of the independent variable. This assumption doesn’t hold for binary variables, because the variance for binary variables is PQ; the maximum variance is .25 when 50 percent of the data are 1s. The variance decreases as you move toward more extreme values. For example, when P =.10, the variance is .1*.9 = .09, so as P approaches 1 or zero, the variance approaches zero.
- Significance testing of the logistic regression coefficient weights assumes that prediction errors (Y – Y’) are normally distributed. Because the dependent variable Y only takes the values 0 and 1, this assumption is difficult to justify. Therefore, tests of regression weights are suspect if you use linear regression with a binary dependent variable [6].
Comparison with Discriminant Analysis
Discriminant analysis is a classification method that gets its name from discriminating — the act of recognizing a difference between certain characteristics. The two goals are:
- Construction of a classification method to separate members of a population.
- Using the classification method to allocate new members to groups within the population.
Discriminant Analysis is used when you have a set of naturally formed groups and you want to find out which continuous variables discriminate between them. The simplest example of DA is to use a single variable to predict where a member will fall in a population. For example, using high school GPA to predict whether a student will drop out of college, graduate from college, or graduate with honors. A more complex example: you might want to find out which variables discriminate between credit applicants who are a high, medium, or low risk for default. You could collect data on credit card holder characteristics and use that information to determine what variables are the best predictors for whether a particular person will be a high, medium, or low risk. New observations (in this case, new applicants) could then be allocated to a particular group. As well as the credit and banking industries, other uses for Discriminant Analysis include:
- Developing facial recognition technology.
- Classifying biological species.
- Classifying tumors.
- Determining the best candidates for college admissions.
Logistic Regression is often preferred over Discriminant Analysis as it can handle categorical variables and continuous variables. Logistic Regression also does not have as many assumptions associated with it. For example, Discriminant Analysis requires the assumptions of equal variance-covariance within each group, multivariate normality, and the data must be linearly related. Logistic Regression does not have these requirements.
References
[1] Canley, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
[2] An Introduction to Logistic Regression. Retrieved October 27, 2023 from: https://www.appstate.edu/~whiteheadjc/service/logit/intro.htm
[3] Edgar, R. & Manz, O. (2017). Exploratory Study. Research Methods for Cyber Security.
[4] Logistic Regression. Retrieved October 27, 2023 from: http://faculty.cas.usf.edu/mbrannick/regression/Logistic.html
[5] Penn State. Logistic regression. Retrieved October 28, 2023 from: https://online.stat.psu.edu/stat462/node/207/
[6] Jurafsky, D. & Martin, J. (2023). Speech and Language Processing. Draft. Retrieved October 27, 2023 from: https://web.stanford.edu/~jurafsky/slp3/5.pdf
Related Articles
Hosmer-Lemeshow Goodness of Fit test. What are Log Odds? Check out our YouTube channel for hundreds of videos on elementary statistics and probability.