< Probability and statistics definitions < Errors in statistics
What are errors in statistics?
Many types of errors can creep into statistical analysis, each of which can negatively influence outcomes or even render an entire experiment null and void. Therefore, when designing and interpreting experiments or surveys, it is important to carefully consider the implications of each type of error.
Common types of errors in statistics include:
- Discretization error
- Measurement error
- Modeling error
- Numerical error
- Prediction error
- Sampling and non-sampling error
- Systematic and random errors
- True Error
- Type I, II, III and IV errors.
1. Discretization Error
In numerical analysis, computational physics, and simulation, discretization error occurs when a function of a continuous variable is represented on a computer through a limited number of evaluations. For instance, on a lattice — which is an arrangement of points in space often used to represent a continuous function on a computer. Reducing discretization error often involves using a more finely spaced lattice, which comes at a higher computational cost.
Discretization error can happen as a result of piecewise approximation, which can be reduced by using more complex (higher order) shape functions or smaller elements [1]. Although higher order shape functions — higher degree polynomials — can better approximate a continuous function, this also comes at a higher computational cost.
2. Measurement Error
Measurement Error (also called observational error) is the difference between a measured quantity and its true value. It includes random error (naturally occurring errors that are to be expected with any experiment) and systematic error (caused by a mis-calibrated instrument that affects all measurements).
When measuring something, error of some kind is always involved. For example, a faulty instrument can cause errors, but so can the measurement environment, or mistakes made by the person taking the measurement.
3. Modeling Error
Modeling error is the difference between the true value of the parameter — the value that is actually present in the population you are modeling — and the model’s estimate of this parameter. When you design a system, there will always be some modeling error present. This error can stem from assumptions made during the modeling process or a problem with the data used to fit the model (e.g., faulty data collection practices).
One type of modeling error is modeling bias, which occurs when the model consistently underestimates or overestimates the true parameter value.
4. Numerical error
A numerical error occurs in a calculation in two ways.
- Rounding error happens because computations involving floating-point values have finite precision. Although increasing the number of digits in a representation reduces the magnitude of roundoff errors, any representation with a limited number of digits will still result in some degree of roundoff error for countless real numbers [2].
- Truncation error is the discrepancy between the exact mathematical solution and the approximate solution. Numerical error arises due to the limited number of significant digits maintained by a computer. [1]
5. Prediction error
Prediction error quantified how well a model predicts the response variable in regression analysis. There are a couple of ways to go about this:
- Cross validation is useful with small samples [3]. Cross validation is a resampling method that uses different parts of the data to test and train a model on different iterations.
- Calculating a model score via a method such as Mallows’ Cp, Akaike information criterion (AIC), and Bayesian information criterion (BIC).
Note that sometimes, the term prediction error is used informally to refer to any error in predictions or residuals in regression analysis.
6. Sampling and non-sampling errors in statistics
Sampling error is a random error that occurs when a sample doesn’t accurately represent the entire population. This error arises when a sample is used instead of conducting a complete population census. It refers to the discrepancy between an estimate based on sample data and the true value that would result from a census. Sampling errors don’t occur in a census since the values are derived from the entire population.
Sampling error can transpire when:
- The proportions of different characteristics in the sample don’t mirror the proportions in the entire population. For example, if we’re sampling men and women and know that the population is 51% women and 49% men, our sample should aim for similar proportions.
- The sample size is too small. In general, the larger the sample, the better that sample represents the population and the smaller the sampling error. A sample size of 10 people taken from the same population of 1,000 will very likely give you a very different result than a sample size of 100.
- Some methods are more likely to result in sampling errors. Random sampling methods are almost always your best bet to avoid these errors.
- Populations with higher heterogeneity often result in larger sampling errors.
Non-sampling error causes data values to deviate from the “true” population value. This is due to poor data collection methods (such as faulty instruments or inaccurate data recording), selection bias, non response bias (where individuals don’t want to or can’t respond to a survey), or other mistakes in collecting the data. Increasing the sample size will not reduce these errors. They key is to avoid making the errors in the first place with a well-planned design for the survey or experiment.
7. Systematic and random errors in statistics
Systematic error, also called systematic bias, happens when consistent and repeatable errors occur due to faulty equipment or a flawed experimental design. On the other hand, random error, also known as unsystematic error, system noise, or random variation, lacks a pattern. Random error is unpredictable and usually unavoidable. It can be minimized by calculating the average measurement from a set of measurements or increasing the sample size.
- Random errors are arbitrary, unpredictable, and can’t be replicated through repeat experiments. These error might be too big, too small, or a combination of both — varying randomly each time you record data.
- Systematic errors result in consistent deviations, either in fixed amounts (e.g., an ounce) or proportions (e.g., 105% of the true value). The deviations are usually in the same direction (either too small or too large but not both at the same time). Improperly calibrated or misused equipment is usually the cause. Conducting the experiment multiple times will consistently result in the same error.
Types of systematic error:
- Offset Error: occurs when the instrument is not reset to zero before weighing items. For instance, a kitchen scale has a “tare” button that zeros the scale and container prior to adding contents. This ensures the weight of the container is not included in the readings. If the tare is not set correctly, all readings will have offset error.
- Scale Factor Errors: occurs when measurements are consistently proportional to the true value. For example, a stretched measuring tape that is 101% of its original size will consistently yield results that are 101% of the true value.
Detecting and preventing systematic error can be challenging. To avoid these errors, it is important to understand the limitations of your equipment and have a clear understanding of how the experiment works. This will help identify areas that may be susceptible to systematic errors.
8. True Error
True error is the difference between the true value of a quantity and the observed measurement [4].
In hypothesis testing, true error is the accuracy of a hypothesis. It describes the error rate of a hypothesis across an unknown distribution of examples (i.e., the distribution of examples that the hypothesis will be applied to is not known in advance). It represents the probability of a single randomly selected example being misclassified [5].
9. Type I, II, III and IV Errors in statistics
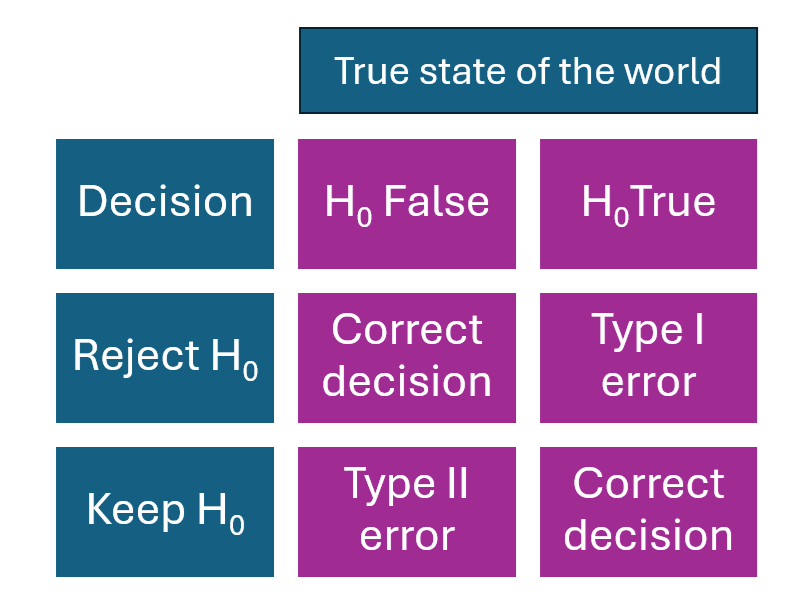
Type I, II, III, and IV errors in statistics are all possible in hypothesis testing. They refer to the possibility of making an incorrect decision about supporting or rejecting the null hypothesis.
- Type I error refers to the erroneous rejection of a true null hypothesis.
- Type II error occurs when a false null hypothesis is not rejected.
- Type III error occurs when the null hypothesis is correctly rejected but for the wrong reason.
- Type IV errors happen when the null hypothesis is correctly rejected, but the interpretation of the results is flawed [6]. Common reasons for Type IV errors include aggregation bias (assuming that what holds true for a group applies to individuals) and conducting inappropriate tests for the data. Collinearity among predictors can also contribute to Type IV errors.
References
- Bettig, B. Modeling Errors and Accuracy.
- Numerical Errors.
- Johari, R. MS&E 226: Fundamentals of Data Science Lecture 5: In-sample estimation of prediction error
- Muth, J. (2006). Basic Statistics and Pharmaceutical Statistical Applications, Second Edition (Pharmacy Education Series). Chapman and Hall/CRC.
- Mitchell, T. (1997). Machine Learning. 1st edition. McGraw-Hill.
- Ottenbacher KJ. Statistical conclusion validity and type IV errors in rehabilitation research. Arch Phys Med Rehabil. 1992 Feb;73(2):121-5. PMID: 1543405.