Regression Analysis > Cook’s Distance
What is Cook’s Distance?
Cook’s distance, Di, is used in Regression Analysis to find influential outliers in a set of predictor variables. In other words, it’s a way to identify points that negatively affect your regression model. The measurement is a combination of each observation’s leverage and residual values; the higher the leverage and residuals, the higher the Cook’s distance.
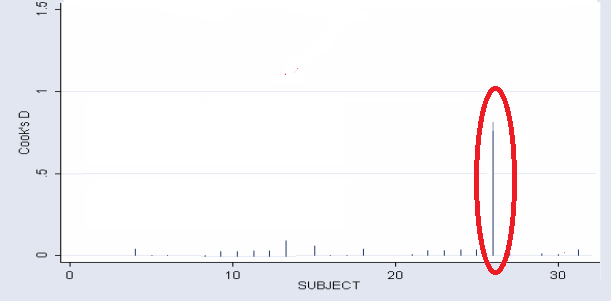
Several interpretations for Cook’s distance exist. There isn’t a universally accepted rule for cut off points.
- One interpretation is to investigate any point over 4/n, where n is the number of observations.
- Other authors suggest that any “large” Di should be investigated. How large is “too large”? The consensus seems to be that a Di value of more that 1 indicates an influential value, but you may want to look at values above 0.5. Any value that sticks out from the other (like the one in the above chart) should also be investigated.
- An alternative (but slightly more technical) way to interpret Di is to find the potential outlier’s percentile value using the F-distribution. A percentile of over 50 indicates a highly influential point.
If you have a lot of points with large Di values, that could indicate a problem with your regression model in general.
Formula
Technically, Cook’s D is calculated by removing the ith data point from the model and recalculating the regression. It summarizes how much all the values in the regression model change when the ith observation is removed. The formula for Cook’s distance is:
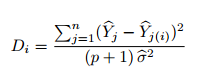
As this can get quite cumbersome by hand, you’ll want to use software like Minitab or SPSS to do it.
In Minitab:
- Go to Regression > Regression.
- Click “Storage” then select “Cook’s Distance.”
- Click “OK.”
A COOK column will appear in your data cells with the Cook’s D values.
Reference:
Cook, R. Dennis (February 1977). “Detection of Influential Observations in Linear Regression”. Technometrics (American Statistical Association)).