< Statistics Definitions < Parzen window estimation
What is Parzen Window Estimation?
Parzen window estimation (PWE), also called kernel density estimation (KDE), is a non-parametric technique used to estimate a random variable’s probability density function (pdf). It is named after Emanuel Parzen, who developed the method.
Unlike parametric estimation methods, non-parametric estimation methods such as PWE make bare-bones assumptions about the underlying probability distribution. For example, one assumption with PWE is that the underlying pdf is continuous so that a kernel function — which quantifies similarity between pairs of data points — can smoothly approximate it.
The kernel function is often called a “window.” The window is centered over each data point and spreads out over a certain range or bandwidth, assigning weights to locations based on distance from the central point. The main purpose of the window is to find the influence each data point has on the estimation of the probability density at various locations. The choice of kernel function and its bandwidth (or window width) influence the estimator’s performance.
Running Parzen Window Estimation
The Parzen window estimator for a univariate dataset {x1, x2,…,xn} is defined as:
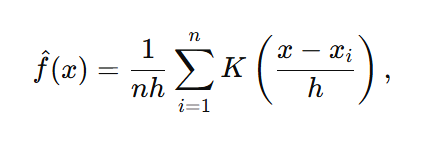
where:
- f-hat(x) is the estimated probability density function at point x.
- n is the number of data points.
- h is the bandwidth or window width.
- K is the kernel function, which is typically a symmetric, non-negative function that integrates to one.
The Gaussian kernel is a popular choice for the kernel function due to its smoothness and mathematical properties. It is defined as:
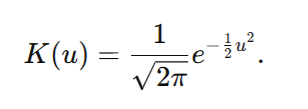
Other choices include the Epanechnikov kernel and uniform kernel.
The bandwidth controls the width of the kernel function and significantly affects the estimator’s bias and variance:
- Small h = a narrow kernel that captures more of the data’s local structure but might result in high variance and overfitting.
- Large h = a wider kernel, which smooths out data more but might introduce bias and underfitting.
Methods such as cross-validation are often used to choose an optimal h.
For a -dimensional (multidimensional) dataset, the estimator becomes:
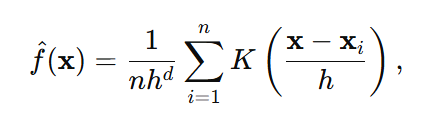
where x and xi are d-dimensional vectors. You must define the kernel function in multiple dimensions, often as a product of univariate kernels or using a multivariate Gaussian kernel.
Advantages and Disadvantages
Parzen window estimation has several advantages:
- It consistently converges to the true underlying density as the sample size approaches infinity.
- As it is non-parametric, that makes it more flexible than parametric methods, especially for complex and multimodal data.
- The smooth density function from PWE is easy to visualize.
However, there are also challenges:
- PWE is computationally intensive, especially for large datasets.
- Curse of Dimensionality: In high-dimensional spaces, the volume of the space increases exponentially, leading to sparser data and less reliable density estimates.
- Bandwidth Selection: Choosing the appropriate bandwidth, which significantly affects the estimator’s performance, is complex and cannot be solved easily.