The Hidden Markov Model (HMM) is a relatively simple way to model sequential data. A hidden Markov model implies that the Markov Model underlying the data is hidden or unknown to you. More specifically, you only know observational data and not information about the states. In other words, there’s a specific type of model that produces the data (a Markov Model) but you don’t know what processes are producing it. You basically use your knowledge of Markov Models to make an educated guess about the model’s structure.
What is a Markov Model?
In order to uncover the Hidden Markov Model, you first have to understand what a Markov Model is in the first place. Here I’ll create a simple example using two items that are very familiar in probability: dice and bags of colored balls.
The model components, which you’ll use to create the random model, are:
- A six-sided red die.
- A ten-sided black die.
- A red bag with ten balls. Nine balls are red, one is black.
- A black bag with twenty balls. One ball is red, nineteen are black.
“Black” and “Red” are the two states in this model (in other words, you can be black, or you can be red).
Now create the model by following these steps:

- EMISSION STEP: Roll a die. Note the number that comes up. This is the emission. In the above graphic, I chose a red die to start (arbitrary — I could have chosen black) and rolled 2.
- TRANSITION STEP: Randomly choose a ball from the bag with the color that matches the die you rolled in step 1. I rolled a red die, so I’m going to choose a ball from the red bag. I pulled out a black ball, so I’m going to transition to the black die for the next emission.
You can then repeat these steps to a certain number of emissions. For example, repeating this sequence of steps 10 times might give you the set {2,3,6,1,1,4,5,3,4,1}. The process of transitioning from one state to the next is called a Markov process.
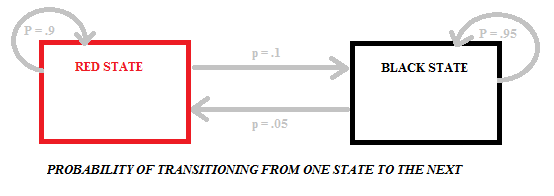
Transitioning from red to black or black to red carries different probabilities as there are different numbers of black and red balls in the bags. The following diagram shows the probabilities for this particular model, which has two states (black and red):
Hidden Markov Model Notation
λ = (A,B,π), is shorthand notation for an HMM. Other notation is used in Hidden Markov Models:
- A = state transition probabilities (aij)
- B = observation probability matrix (bj(k))
- N = number of states in the model {1,2…N} or the state at time t →st
- M = number of distinct observation symbols per state
- Q = {q0, q1, . . . , qN−1} = distinct states of the Markov process
- T = length of the observation sequence
- V = {0, 1, . . . , M − 1} = set of possible observations
- O = (O0, O1, . . . , OT −1) = observation sequence
- π = initial state distribution (πi)
- s = state or state sequence (s1, s2… sn)
- xk = hidden state
- zk = observation.
Three Basic Problems
Three basic problems can be solved with Hidden Markov Models:
- Given the Hidden Markov Modelλ = (A, B, π) and a sequence of observations O, find the probability of an observation P(O | λ). This is sometimes called the Evaluation Problem.
- Given the Hidden Markov Modelλ = (A, B, π) and an observation sequence O, find the most likely state sequence (s1, s2… sn). This is sometimes called a Decoding Problem.
- Find an observation sequence (O1, O2…On and Hidden Markov Model λ = (A, B, π) that maximizes the probability of O. This is sometimes called a Learning Problem or Optimization Problem.
References:
Rabiner, L.R. “A tutorial on hidden Markov models and selected applications in speech recognition”, Proceedings of the IEEE, vol.77, pp. 257-286, Feb. 1989.
Stamp, M. (2013). A Revealing Introduction to Hidden Markov Models. Retrieved 8/6/2013 from: http://www.cs.sjsu.edu/~stamp/RUA/HMM.pdf