The contingency coefficient is a coefficient of association that tells whether two variables or data sets are independent or dependent of each other. It is also known as Pearson’s Coefficient (not to be confused with Pearson’s Coefficient of Skewness).
It is based on the chi-square statistic, and is defined by:
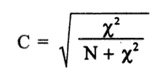
In this formula:
- χ2 is the chi-square statistic,
- N is the total number of cases or observations in our analysis/study,
- C is the contingency coefficient.
Understanding Contingency Coefficient Values
The contingency coefficient helps us decide if variable b is ‘contingent’ on variable a. However, it is a rough measure and doesn’t quantify the dependence exactly; It can be used as a rough guide:
- If C is near zero (or equal to zero) you can conclude that your variables are independent of each other; there is no association between them.
- If C is away from zero there is some relationship; C can only take on positive values.
The larger the table your chi-squared coefficient is calculated from, the closer to 1 a perfect association will approach. That’s why some statisticians suggest using the contingency coefficient only if you’re working with a 5 by 5 table or larger.
When to Use a Contingency Coefficient
A contingency coefficient is particularly informative if you’re working with a large sample, and you don’t need to find out if an association is complete or not—just whether or not the association exists.
Other alternative measures of association include the phi coefficient (which has the same weak point as our C; never reaching one), and Cramers V. Cramers V is often preferred because with perfect association, it becomes exactly 1 no matter how large the table.
References
Tattao, L. (2007). Basic Concepts in Statistics. Retrieved from https://books.google.com/books?id=og4a_700L-4C on January 10, 2018
Measures of Association. Retrieved from http://uregina.ca/~gingrich/ch11a.pdf on January 10, 2018