Statistics Definitions > Friedman’s Test
What is Friedman’s Test?
Friedman’s test is a non-parametric test for finding differences in treatments across multiple attempts. Nonparametric means the test doesn’t assume your data comes from a particular distribution (like the normal distribution). Basically, it’s used in place of the ANOVA test when you don’t know the distribution of your data.
Friedman’s test is an extension of the sign test, used when there are multiple treatments. In fact, if there are only two treatments the two tests are identical.
Running the test
Your data should meet the following requirements:
- Data should be ordinal (e.g. the Likert scale) or continuous,
- Data comes from a single group, measured on at least three different occasions,
- The sample was created with a random sampling method,
- Blocks are mutually independent (i.e. all of the pairs are independent — one doesn’t affect the other),
- Observations are ranked within blocks with no ties.
The null hypothesis for the test is that the treatments all have identical effects, or that the samples differ in some way. For example, they have different centers, spreads, or shapes. The alternate hypothesis is that the treatments do have different effects.
1. Prepare your data for the test.
Step 1: Sort your data into blocks (columns in a spreadsheet).for this example, we have 12 patients getting three different treatments.
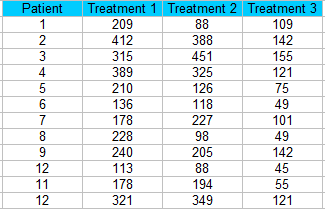
Step 2: Rank each column separately. The smallest score should get a rank of 1. I am ranking across rows here so each patient is being ranked a 1, 2, or 3 for each treatment.
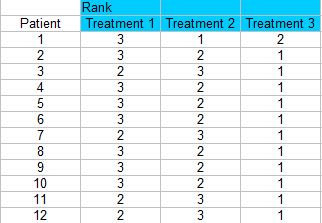
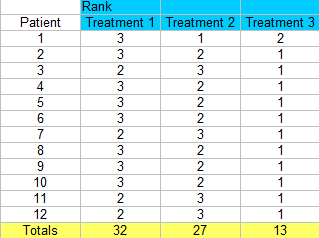
Step 3: Sum the ranks (find a total for each column).
2. Run the Test
Note: This test isn’t usually run by hand, as the calculations are time consuming and labor-intensive. Nearly all popular statistical software packages can run this test. However, I’m including the manual steps here for reference.
Step 4: Calculate the test statistic. You’ll need:
- n: the number of subjects (12)
- k: the number of treatments (3)
- R: The total ranks for each of the three columns (32, 27, 13).
Insert these into the following formula and solve:
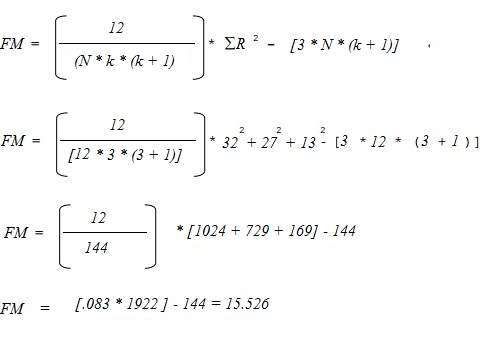
Step 5: Find the FM critical value from the table of critical values for Friedman (see table below).
Use the k=3 table (as that is how many treatments we have) and an alpha level of 5%. You could choose a higher or lower alpha level, but 5% if fairly common — so use the 5% table if you don’t know your alpha level.
Looking up n-12 in that table, we find a FM critical value of 6.17.
Step 6: Compare the calculated FM test statistic (Step 4) to the FM critical value (Step 5). Reject the null hypothesis if the calculated F value is larger than the FM critical value.:
- Calculated FM Test Statistic = 15.526.
- FM Critical value from table = 6.17.
The calculated FM statistic is larger, so you would reject the null hypothesis.
Friedman’s ANOVA by Ranks Critical Value Table
Three tables according by “k”.
If your k is over 5, or your n is over 13, use the chi square critical value table in Step 5 to get the critical value.
k=3
| N | α <.10 | α ≤.05 | α <.01 |
| 3 | 6.00 | 6.00 | — |
| 4 | 6.00 | 6.50 | 8.00 |
| 5 | 5.20 | 6.40 | 8.40 |
| 6 | 5.33 | 7.00 | 9.00 |
| 7 | 5.43 | 7.14 | 8.86 |
| 8 | 5.25 | 6.25 | 9.00 |
| 9 | 5.56 | 6.22 | 8.67 |
| 10 | 5.00 | 6.20 | 9.60 |
| 11 | 4.91 | 6.54 | 8.91 |
| 12 | 5.17 | 6.17 | 8.67 |
| 13 | 4.77 | 6.00 | 9.39 |
| ∞ | 4.61 | 5.99 | 9.21 |
k=4
| N | α <.10 | α ≤.05 | α <.01 |
| 2 | 6.00 | 6.00 | — |
| 3 | 6.60 | 7.40 | 8.60 |
| 4 | 6.30 | 7.80 | 9.60 |
| 5 | 6.36 | 7.80 | 9.96 |
| 6 | 6.40 | 7.60 | 10.00 |
| 7 | 6.26 | 7.80 | 10.37 |
| 8 | 6.30 | 7.50 | 10.35 |
| ∞ | 6.25 | 7.82 | 11.34 |
k=4
| N | α <.10 | α ≤.05 | α <.01 |
| 3 | 7.47 | 8.53 | 10.13 | 4 | 7.60 | 8.80 | 11.00 | 5 | 7.68 | 8.96 | 11.52 | ∞ | 7.78 | 9.49 | 13.28 |
Reference:
Friedman’s Two-way Analysis of Variance by Ranks — Analysis of k-Within-Group Data with a
Quantitative Response Variable. Retrieved 7-17-2016 from: http://psych.unl.edu/psycrs/handcomp/hcfried.PDF