Statistics Definitions > > Clustered Standard Errors
You may want to read this article first: What is the Standard Error of a Sample?
What are Clustered Standard Errors?
Clustered Standard Errors(CSEs) happen when some observations in a data set are related to each other. This correlation occurs when an individual trait, like ability or socioeconomic background, is identical or similar for groups of observations within clusters. Panel data (multi-dimensional data collected over time) is usually the type of data associated with CSEs.
For example, let’s say you wanted to know if class size affects SAT scores. Specifically, you think that smaller class size leads to better SAT scores. You collect panel data for dozens of classes in dozens of schools. As this is panel data, you almost certainly have clustering. Teachers might be more efficient in some classes than other classes, students may be clustered by ability (e.g. special education classes), or some schools might have better access to computers than others. According to Cameron and Miller, this clustering will lead to:
- Standard errors that are smaller than regular OLS standard errors.
- Narrow confidence intervals.
- T-statistics that are too large.
- Misleadingly small p-values.
Incorrect standard errors violate of the assumption of independence required by many estimation methods and statistical tests and can lead to Type I and Type II errors.
Adjusting for Clustered Standard Errors
Accurate standard errors are a fundamental component of statistical inference. Therefore, If you have CSEs in your data (which in turn produce inaccurate SEs), you should make adjustments for the clustering before running any further analysis on the data.
Hand calculations for clustered standard errors are somewhat complicated (compared to your average statistical formula). For example, this snippet from The American Economic Review gives the variance formula for the calculation of the clustered standard errors:
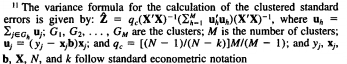
It’s usually not necessary to perform these adjustments by hand as most statistical software packages like Stata and SPSS have options for clustering. When you specify clustering, the software will automatically adjust for CSEs.
One way to control for Clustered Standard Errors is to specify a model. For example, you could specify a random coefficient model or a hierarchical model. However, accuracy of any calculated SEs completely relies upon you specifying the correct model for within-cluster error correlation. A second option is Cluster-Robust Inference, which does not require you to specify a model. It does, however, have the assumption that the number of clusters approaches infinity (Ibragimov & Muller).
References
Cameron and Miller. A Practitioner’s Guide to Cluster-Robust Inference
Ibragimov, R., & Muller, U. Inference with Few Heterogeneous Clusters.
Primo, D. the practical researcher. Estimating the Impact of State Policies and
Institutions with Mixed-Level Data