The Chinese Restaurant Process is a metaphorical way for how a Dirichlet process generates data. The Dirichlet process models randomness of a probability mass function (PMF) with unlimited options (e.g. an unlimited amount of dice in a bag). It’s specifically called the Chinese Restaurant Process because the algorithm’s creators, Jim Pitman and Lester Dubins, named it after seeing massive Chinese restaurants in San Francisco’s Chinatown (Aldous, 1983; Stanford 2016).
Simple Example of the Chinese Restaurant Process
The following example (adapted from Bello eet, al, 2008) is about as simple as it gets. Don’t be tempted to try and assign simple probabilities like 1/8 or 4/32 to the tables. You’re dealing with infinite amounts here, so the usual probability techniques don’t work. In fact, figuring out the probability of sitting at any one table out of an infinite number of tables involves the use of a positive scalar hyperparameter, and is time consuming to solve— even for a computer. For more on choosing hyperprameters, see Amir-Ahmadi et. al’s Choosing Prior Hyperparameters.
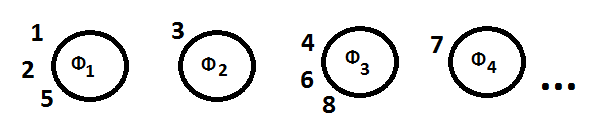
In the above example, customers 1, 3, 4, and 7 are sat at empty tables; customers 2, 5, 6, and 8 are sat at existing tables. The number of tables in the restaurant is infinite.
When customer 1 enters, he can sit anywhere he likes. Customer 2 can sit in any empty seat, with the following probabilities:
- Table 1: 1 / (1 + α)
- New Table (i.e. any empty table): α / (1 + α)
The probabilities for where customer 9 will sit are as follows:
- Table 1: 3 / (8 + α)
- Table 2: 1 / (8 + α)
- Table 3: 3 / (8 + α)
- Table 4: 1 / (8 + α)
- New Table: α / (8 + α)
The numerator is the number of people already sat at a particular table, and the denominator is the number of customers in the restaurant (i – 1) plus α (a positive scalar hyperparameter, which is set before the process starts).
- The probability of the ith customer sitting at an existing table is nk / (α + i – 1),
- The probability of the ith customer sitting at a new table is α / (α + i – 1).
As more people sit at a particular table, those tables increase in popularity, so new patrons are less likely to sit at empty tables.
References
Aldous, D. J. (1985). “Exchangeability and related topics”. École d’Été de Probabilités de Saint-Flour XIII — 1983. Lecture Notes in Mathematics. 1117. pp. 1–1.
Amir-Ahmadi et. al (2016). Choosing Prior Hyperparameters. Retrieved February 13, 2018 from: https://www.richmondfed.org/-/media/richmondfedorg/publications/research/working_papers/2016/pdf/wp16-09.pdf
Bello, J. et. al (2008). ISMIR 2008: Proceedings of the 9th International Conference of Music Information Retrieval. Lulu Press.
Stanford University (2016). Chinese Restaurant Viewpoint. Retrieved February 13, 2018 from: https://cs.stanford.edu/~ppasupat/a9online/1083.html